
Generative AI: Everything You Need to Know
And How to Use it for Your Career and Industry

AI is not tomorrow, it’s today.
You better wake up and get on it. If you don’t, others will learn to use AI tools before you, increase their productivity, take your job or your company, and leave you in the dust.
Instead, you can quickly get up to speed and bring the future to the present.
A few weeks ago, I didn’t know that much about Generative AI. Since then, I’ve spent days studying it. I’ve summarized it all in two articles. This is the first one, to get up to speed quickly. You’ll get:
Examples of the latest in Generative AI, so you start forming an idea of what you could do with it.
A mental framework for how to think about AI.
The most common AI tools today.
Buckle up!
The Cambrian Explosion of Generative AI
The Crow, an AI movie, won the Cannes festival this year in the category of short films.
And this is just the beginning. This movie has the eerie artifacts of early AI, and required a dancer as a baseline, to modify into a crow’s movements. But if it can do this now, what will it do tomorrow?
Look at this video:
These guys took AI-generated images through Midjourney, animated the faces with Reface, panned the camera through PopPic, and altered voices through Altered.ai.
Or this one:
If this type of stuff gets you excited, scared, and a bit lost, good. By the end of the article, you should only feel excited. For that, let’s jump to the core of Generative AI, the type of AI that generates new things rather than process existing data. How should you think about it?
AI has three main components: text, images, and sound. Then, each piece can be further divided and combined. For example, video is a set of linked images, with a combination of two types of sounds, music and speech.
Text
At the core of everything is text, because it is the closest to thinking. If you want to chat with an AI, ask it questions, create a relationship with it, or create realistic characters, the core is a text-based AI.
Conversation
The most famous is GPT-3, from OpenAI, the most advanced Generative AI company today, also behind other advanced AI models like Whisper and DALL-E (we’ll talk about them in detail). There are also other models, like PaLM and LaMDA1.
If you’ve seen people chatting with AIs and getting confused about whether they are alive or not, odds are they were talking with one of the three. Here’s an example that I shared in the August 2022 Updates article:

Here’s one way somebody used GPT-3 to brainstorm business ideas, and then asks it to tell him about possible downsides, to refine the ideas.



A few years ago, there was a frenzy of AI chatbots. They didn’t succeed, because they were dumb. They were dumb, because GPT-3 was not here. Now the AI is getting good enough.
You can play with GPT-3 today. It has dozens of use cases, like:
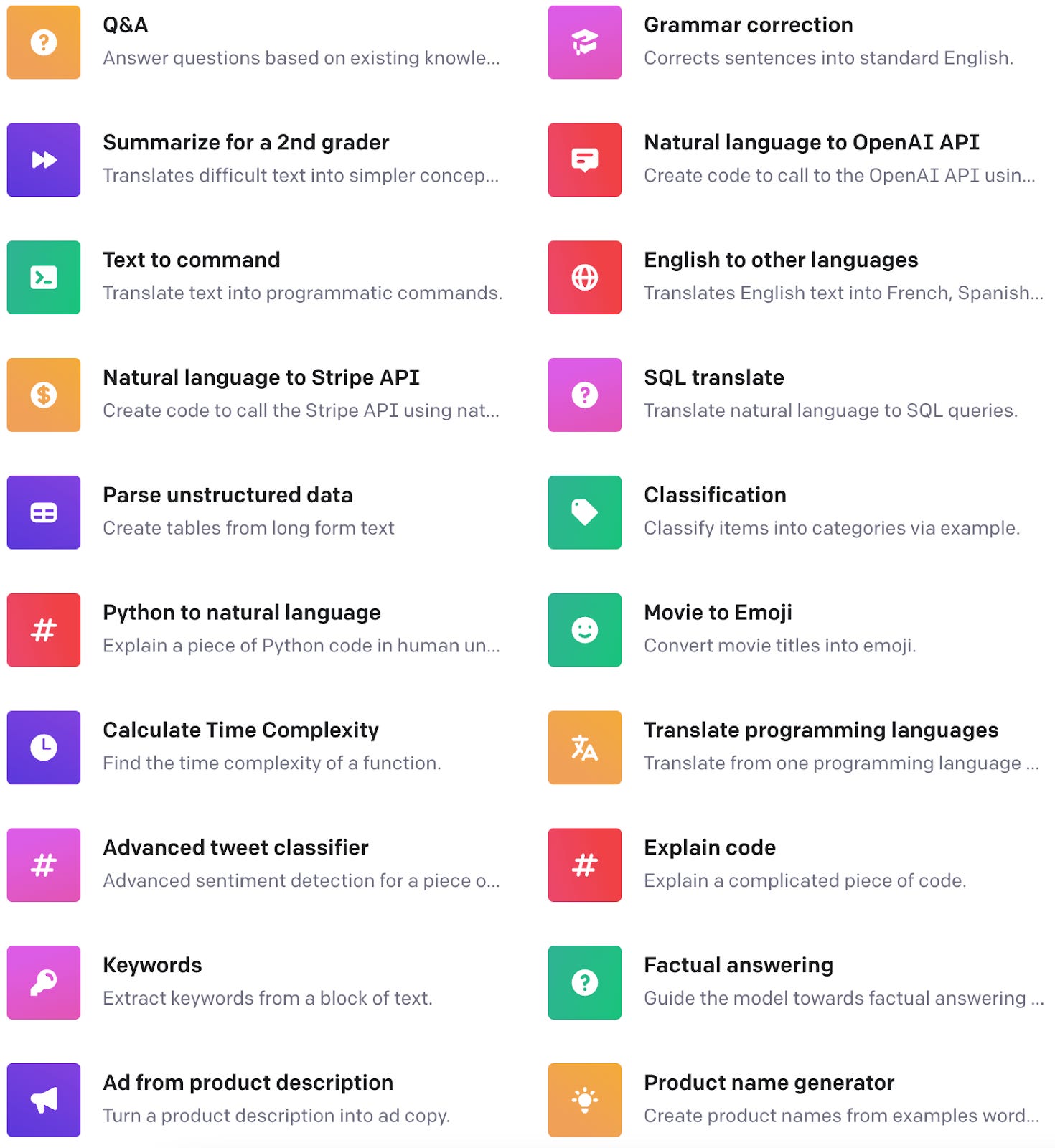
Here are some examples of companies working in the space2:
Write text for you: emails, ads, articles… Companies doing this include Jasper3, Copy.ai4, Writer, Writesonic, Peppertype, Hypotenuse, Anyword, Copysmith, Scalenut, Postearly, Lex, Rytr5…
Sudowrite is focused on literature, and helps authors express themselves more poignantly.
Summari summarizes text.
Explainpaper.com does the same for scientific papers. A godsend.
Otter and Fireflies transcribe meetings on top of summarizing them for you.
Character.ai created a marketplace for bots.
It’s not hard to see where this is going: The future of this is the perfect personal assistant, coach, friend, or partner for every one of us.
You might have noticed other interesting use cases in the list I showed above. For example… coding?!
Coding
Indeed, coding can be seen as just translating between a human language and a machine language. Anything that GPT-3 can do for human language, it can do for coding.
You can do all sorts of coding with AI, from auto-completing your code, to asking it to explain a piece of code you don’t understand, all the way to simply generating full pieces of code, like in Replit’s7 Ghostwriter.
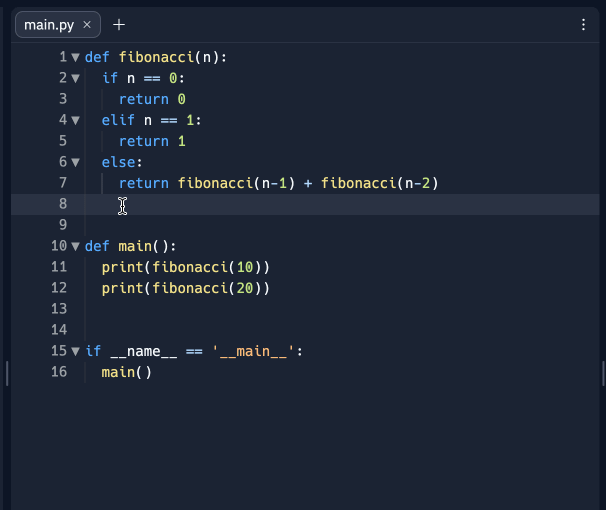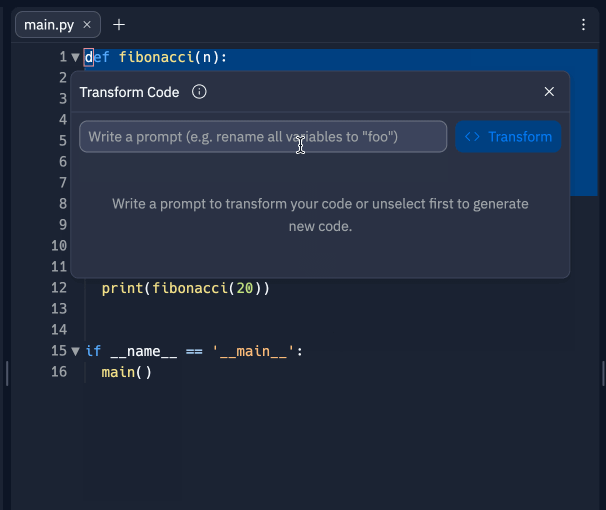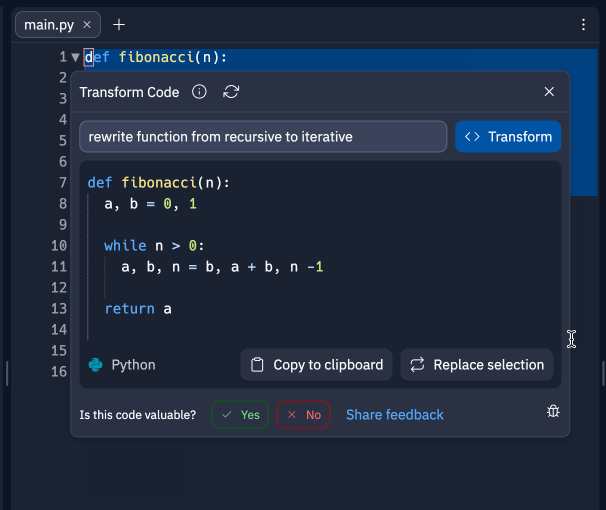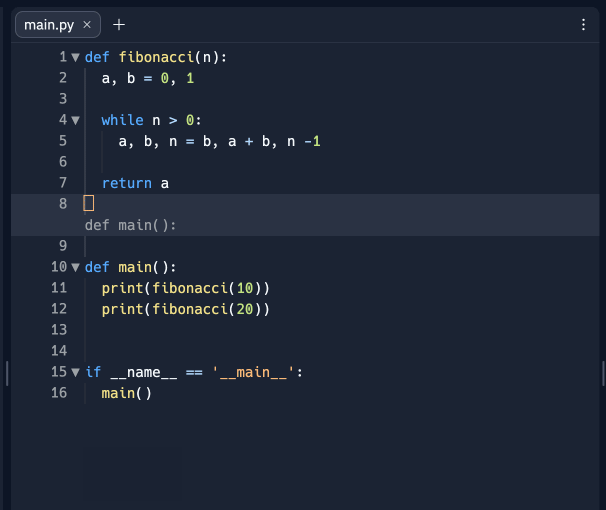
When the code is complex, the AI isn’t there yet. But a large proportion of code is not that complex. That’s what AI can do better and faster than humans.
Here’s an example of AI-enhanced coding by GitHub CoPilot:

Apparently, for the developers who’ve enabled it, 40% of their code is written by CoPilot. Imagine the productivity improvements!
This doesn’t need to be limited to pure coding. Pull requests can be automated. And any language works, like automating spreadsheet formulas.
A more standard use case for text-to-text is translation. Here, the surprising piece is not the concept, but how good it is.
Transcription and Translation
In fact, OpenAI has an AI specifically focused on translation, Whisper, which it released less than two months ago. And it turns out it’s not just good at translation between languages; it’s also amazing at transcription from speech to text. If you think about it, it makes sense, since writing and speech can be seen as just different languages.
For those who’ve used it, it’s unbelievable.


Go to Whisper to see demos.
You know how digital assistants are annoying because they don’t understand what you say? Well, if Whisper works as intended, that problem is in the past. Whisper can understand speech much better than Siri, any other AI you’ve used, or even humans, whether there’s background noise or not, and in many languages, and it can also translate between virtually any language.
It’s not open yet, but you can play with it for free as a developer. The options are infinite. Here are some:
You can use it as a standard transcript tool.
To create a pdf transcript of a youtube video, or automatically add captions.
To create subtitles in other languages.
To automatically record a meeting, transcribe it with Whisper, and summarize it with GPT-3, so that every meeting can be easily digested by anybody.
Do the same for medical conversations, where an AI can suggest ideas for diagnoses in real time
Translate conversations in near-real time!
This leads us to the second big area of Generative AI after text: speech and sound.
Sound
When translating speech between languages, you have different steps: Converting the sounds into intelligible speech, transcribing into the same language, translating into the other language, and then synthesizing the new words into speech.
This means you need to go from sound to text and text to sound. Each of these has its own use cases.
Speech
One of the most famous tools in the text-speech vertical is Descript, which I’ve used recently for the podcasts I’ve recorded. It creates a good transcript of what you said8. But the magic is not from speech to text. It’s the other way around: You can edit the transcript, and it automatically edits the words coming from your mouth! You can rewrite words, and it will say those words for you, in your voice! It can do the same for video apparently, but I didn’t try. Adobe is trying to do something similar for podcasts. Reduct does it for video.
Along the lines of text to speech, with Murf AI you can write any text and it will read it for you in different voices, or you can have it clone your voice. Here’s a quick demo I made:
Wellsaid also allows you to go from text to speech. What about speech in videos? Creating subtitles is becoming trivial, and many companies already offer it. So the most innovative companies focus on other areas. Papercup automatically dubs videos in other languages. Voicemod and Koe Recast allow streamers to change their voice in real time.
I couldn’t use it to clone my voice, but Resemble.ai allowed me to do it. It left me… speechless. It was me! The first time I heard it, for an instant I forgot that it was an AI who had produced it. I thought I had recorded it myself.
Coqui.ai is trying to become a full AI audio studio: Turn text into voice, and then direct the voice’s timbre, tempo, tone, enunciation, emotion, pitch, prosody, rate, duration, contour… Why would you record sound in the future, when it’s easier to create it from scratch?
The most interesting uses are appearing at the fringes of what’s possible. Podcast.ai took the world by storm when it created an entire podcast episode between Joe Rogan and Steve Jobs9. You’d imagine you can barely listen to these podcasts, but in fact they’re reasonable. The voices and intonations are quite accurate, the people are articulate, the topics are right… It’s far from the real thing, still in the uncanny valley, but it’s shockingly closer than I expected. Give it a few more years, and where is this going to go? Live conversations with any person you might want to talk with.
So far, we’ve discussed speech. But there are other sounds that are possible. Most obviously, music.
Music
Do you want to add a soundtrack? You can create it from scratch, from text to music! In this link, you can see somebody who created a tool where you put a prompt (like “astronaut riding a horse”), a few tags (like “space, saxophone, travel”), and it creates a pretty good soundtrack for it!
I created a few samples with Soundraw.io. If they’re truly created with AI, they sound surprisingly good! Better than this. Image-to-music is definitely not there yet.
This is still in its infancy, but you can imagine we’re not far away from truly great AI-generated soundtrack music with prompts. Jukebox, from OpenAI, has crazy samples including vocals!
Sound Effects
The same thing is starting with sound effects, with at least a couple of companies. Once this works well, can you imagine how amazing that would be for sound editors? How many millions of sounds do you need to have the perfect one for every single situation? And even if you have an ample library, it might not be the perfect sound to fit every video. Creating it from scratch would be much better.
These are some of the principles for speech and text. Now let’s move to another sense: the world of visuals.
Images
Text to Images
This is the most famous one. If you already know a lot about it, just jump to the next section. For those of you who want a quick summary of where we’re at in image generation, keep reading.
An AI won the top prize in a painting competition.

The images that AIs can generate are incredible.

Every single one of the pictures below was generated by an AI:

It works by giving an AI a text prompt, and the AI creates an image that corresponds to that.
The first AI to do this was DALL-E, and its successor, DALL-E 2 (you can access the API). But only a few people could access these. Since then, new, more open models have appeared, like Stable Diffusion and Midjourney. You can try some of these tools for free from your browser, like Midjourney, Craiyon10, Stable Diffusion through the Dream Studio tool, photosonic, or Hugging Face. You can also download DiffusionBee to run Stable Diffusion on your computer for free, no technical knowledge needed.
Here’s what Midjourney 3 gave me when I asked it for Roman soldiers harvesting11:

After some iterations and a lot of work, I got this:

These models improve all the time. For example, I just reran the same prompt in the new version of Midjourney, and got this on my first attempt:

Here are some pictures that people have made, with a bit more work:

Sometimes it’s hard to find the right prompts for great images. Some tools are emerging to help: Here’s a prompts guide, and the official one for Midjourney. Other tools allow you to look at amazing pictures that others have created and the prompts they used. You can use Lexica, krea.ai, arthub.ai, Playground.ai, or Promptomania12.
Or, if it’s too hard, simply use GPT-3 to come up with better prompts!

Tools like Stable Diffusion and Midjourney allow you to go from text to image. In a way, what Lexica and Promptomania do is go from images to text. But you can also go from image to image.
Image to Image
Companies like Snapchat have already been using AI to edit pictures on the fly. Plenty other tools have appeared to do that, like:
Image Enlarger increases definition to your pictures.
Autoenhance enhances them automatically.
Remove eliminates backgrounds from images for free.
Magic Eraser deletes elements in a picture.
PhotoRoom combines both: element deletion and background elimination (and also allows you to blur backgrounds).
This tool allows you to create realistic-looking people.
You can take pictures of people or things and put them inside different scenes.
You can try different hairstyles.
You can take pictures and modify them with a prompt.
Some companies try to combine several of these tools, like ClipDrop, which allows you to remove backgrounds, persons, and text, upscale pictures, and change the light.
Other tools allow you to go from a rough sketch to a higher fidelity one in seconds:
You have inpainting and outpainting, where the AI allows you to expand your image, or redo some parts of it.
You can also sketch images and get much better ones with a prompt:

What you’re doing there is simply nudging the AI in the direction of your image.
Or you can iterate with your AI, and add images and inpainting to direct a specific image you might have in mind.
Design
Many of these tools, if slightly adjusted, can be used by designers.
You can
Create a color palette based on a concept.
Come up with icons.
Or patterns.
Or tiles.
Create textures.
You can also create products from scratch:
Or 3D objects:
So you can go from text to text, text to image, image to text, image to image… And since videos are just images in a sequence, the obvious next step is video.
Video
Video is the hardest, but it’s also the end goal. And progress there is every bit as exciting. Taking this idea of videos as combinations of images, you can easily create storyboards:
You can isolate backgrounds and change them on the fly.
Also here.
NeRFs
Or simply create 3D environments!
NeRFs (“Neural Radiance Field) are a type of AI that can take a set of 2D images and create a 3D environment based on them. Then, you can move your camera around that 3D environment. It’s brutal.
This was not created with a drone! It’s just taking pictures with a phone, which then creates the scene!
What about creating full-blown universes with AI? Like this one, where an AI created a 3D model of a city, and an AI converted it into Manga-style13?
3D Objects
You can also extract objects and create 3D versions of them.
Or create them from scratch:
You can try them on:
And make them come to life:
And with humans too!
Humans
I created this video in 10 minutes with an iOS app from a company called Scandy. It gets you one free scan per week.
Then you can act something out, and put a character on top of it:
And if you already have footage you want to just slightly edit to fit some changes, you can do that. For example for dubbing in other languages. Now the mouth fits the language14.
All of this is image to video, or video to video. But there’s also text to video!

Even longer-form video!
You can direct characters and tell them what to do… with text.
With Hour One, Synesthesia, Rephrase.ai, and Jali, you can write stuff, and a human-looking AI will say it for you.
Some companies are trying to put everything in one place. From what I could find, Runway is the one company trying to create the perfect video editing tool, with AI inserted everywhere—the first tweet in this section is from them. You can remove backgrounds, snap images to sounds, reduce noise from images, complete scenes that you never filmed, get video from text prompts… All this help can reduce editing work by 60x.
Others like DeepBrain create AI avatars for you, from visuals to voice.
This stuff is not science fiction. The Amazon Prime show Peripheral used Midjourney to texturize some actors.
Takeaways
So that’s a review of all the big elements we’re seeing in generative AI: text, images, speech, sounds, video, and all their connections. According to the VC firm Sequoia, this is what it all looks like:
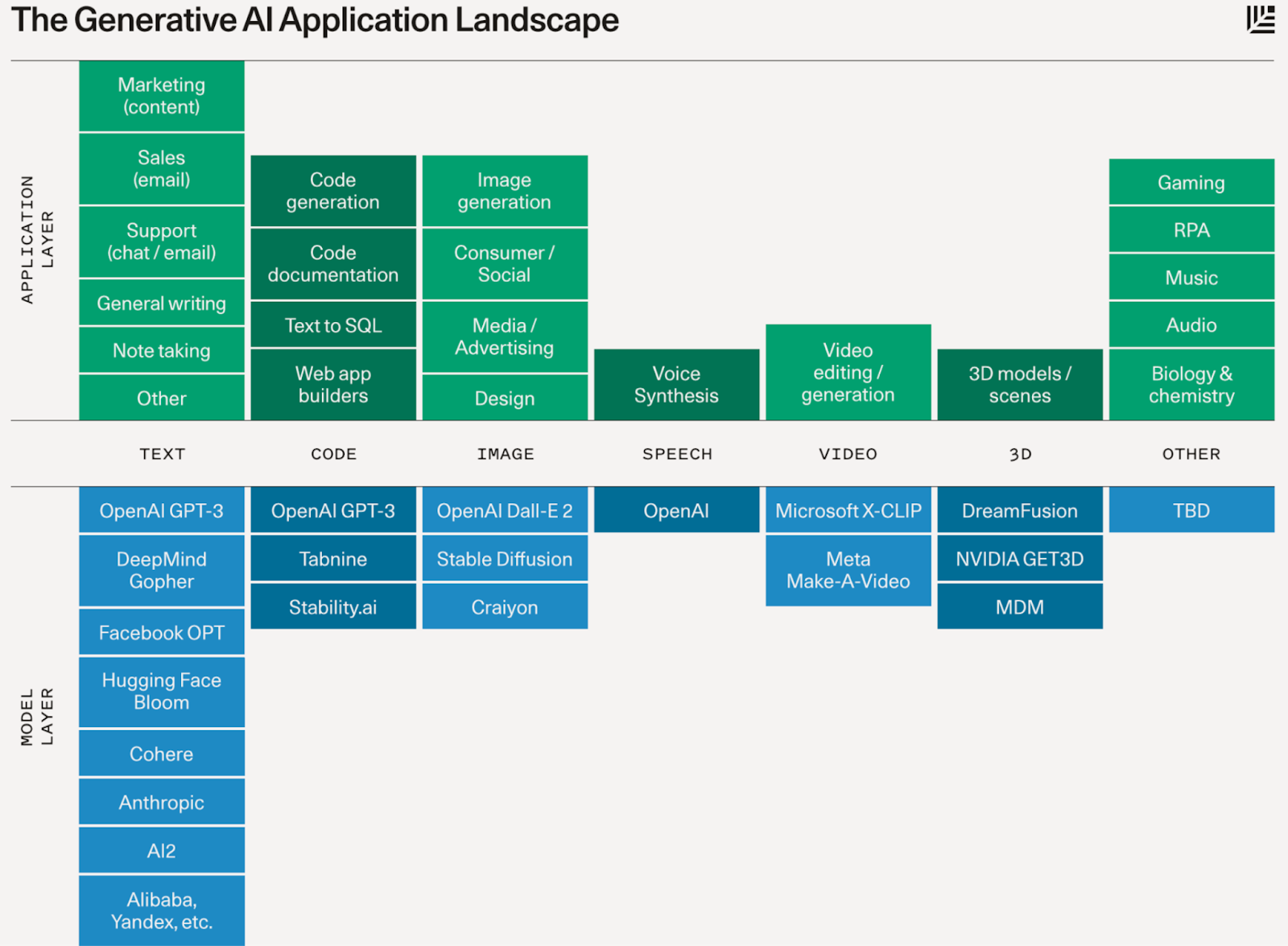
And here is Sequoia’s latest summary of companies working in the space.

Who do you know that needs to learn about Generative AI? Send them this article.
I’m very interested in this, so please send my way any piece that I have missed. And if you know an interesting company in the space, I want to hear about it!
Now the question becomes: How will your industry change based on AI? Your job? What new industries are going to appear? In tomorrow’s—premium—article, I’ll explore how different industries will change: writing, illustration, design, scientific research, marketing, sales, videogames, movies, investing… But also, how new industries will finally explode, like personal assistants and talking with the departed. Subscribe to read it!
If you’re accepted, you can use Google LaMDA’s Test Kitchen.
This list will get stale fast. The idea is not to be up to date, but rather give you a glimpse of what’s happening.
It raised $130M from the likes of Coatue and Bessemer at a $1.5B valuation
With investors like Sequoia, Tiger and others.
Some companies started even before this trend and have done a pretty good job. The most typical example is corrections.Grammarly is the most famous company in the space, and is worth $13B.
In fact it’s a personal assistant, but that use case sounds awfully hard to me to start with. I assume the copy editing is easier and better to start with, which is why I highlight it.
Note: Replit ran a crowdfunding round and I participated. I am a big fan of their project!
Although I’m hearing it’s not as good as Whisper.
They’ve released another episode between Lex Friedman and Richard Feynman since.
Works less well for me.
The actual prompt was: “two roman soldiers harvesting wheat on a field. A third soldier is riding an idle horse and watching the scene. Two villagers are running away in the distance towards a forest that is far away. Hyperrealistic, 8k, unreal engine”
There are also prompt guides for DALL-E, DALL-E 2, Stable Diffusion.
Translation: "After having AI automatically generate a 3D model, I converted the space into a manga style, and then added colors to make it look like an anime. I want to make it possible for AI to freely express things like "Your Name"-style, Ghibli-style, and Disney-style metaverses."
After spending 15 years in the US, dubbing looks weird to me. But growing up in Europe, it was the norm. So if you look at this and get weirded out, consider you might have the chance of not usually needing dubbing. Correcting the mouths is amazing for those who don’t have that luck. And although today it’s a bit weird, you can imagine it getting quite good, fast.
After the camera was developed it was use to verify reality as individual testimony could be biased
Now the word can become “flesh” and imagination “real”. Walking shadows in AI
Honestly, this was as timely and impactful as what put you on the map - Flatten The Curve. No one has put together the full story of state of Gen AI, right at the moment it begins the steep R0.
Well done!