
OpenAI and the Biggest Threat in the History of Humanity
We don’t know how to contain or align a FOOMing AGI

Last weekend, there was massive drama at the board of OpenAI, the non-profit/company that makes ChatGPT, which has grown from nothing to $1B revenue per year in a matter of months.
Sam Altman, the CEO of the company, was fired by the board of the non-profit arm. The president, Greg Brockman, stepped down immediately after learning Altman had been let go.

Satya Nadella, the CEO of Microsoft—who owns 49% of the OpenAI company—told OpenAI he still believed in the company, while hiring Greg and Sam on the spot for Microsoft, and giving them free rein to hire and spend as much as they needed, which will likely include the vast majority of OpenAI employees.

This drama, worthy of the show Succession, is at the heart of the most important problem in the history of humanity.
Board members seldom fire CEOs, because founding CEOs are the single most powerful force of a company. If that company is a rocketship like OpenAI, worth $80B, you don’t touch it. So why did the OpenAI board fire Sam? This is what they said:

No standard startup board member cares about this in a rocketship. But OpenAI’s board is not standard. In fact, it was designed to do exactly what it did. This is the board structure of OpenAI:
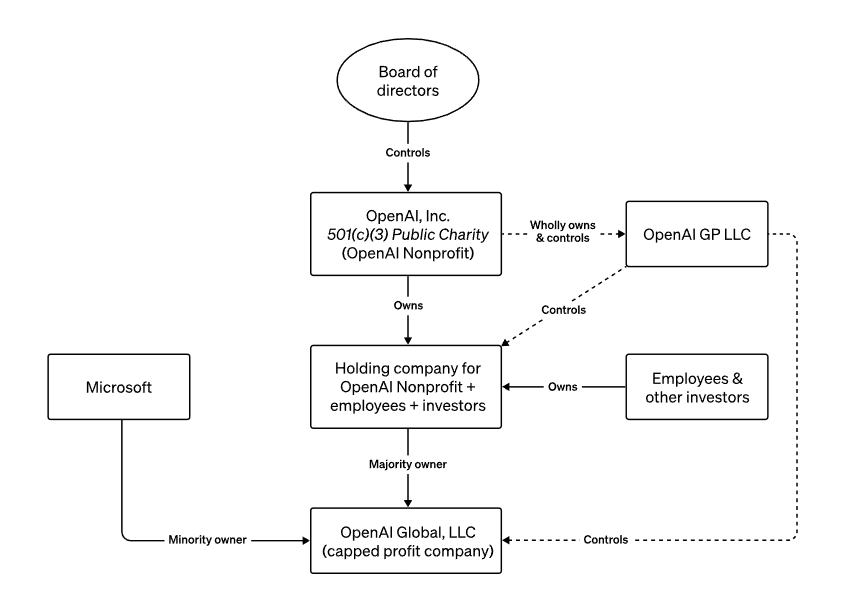
To simplify this, let’s focus on who owns OpenAI the company, at the bottom (Global LLC):
OpenAI the charity has a big ownership of the company.
Some employees and investors also do.
And Microsoft owns 49% of it.
Everything here is normal, except for the charity at the top. What is it, and what does it do?
OpenAI the charity is structured to not make a profit because it has a specific goal that is not financial: To make sure that humanity, and everything in the observable universe, doesn’t disappear.
What is that humongous threat? The impossibility to contain a misaligned, FOOMing AGI. What does that mean? (Skip this next section if you understand that sentence fully.)
FOOM AGI Can’t Be Contained
AGI FOOM
AGI is Artificial General Intelligence: a machine that can do nearly anything any human can do: anything mental, and through robots, anything physical. This includes deciding what it wants to do and then executing it, with the thoughtfulness of a human, at the speed and precision of a machine.
Here’s the issue: If you can do anything that a human can do, that includes working on computer engineering to improve yourself. And since you’re a machine, you can do it at the speed and precision of a machine, not a human. You don’t need to go to pee, sleep, or eat. You can create 50 versions of yourself, and have them talk to each other not with words, but with data flows that go thousands of times faster. So in a matter of days—maybe hours, or seconds—you will not be as intelligent as a human anymore, but slightly more intelligent. Since you’re more intelligent, you can improve yourself slightly faster, and become even more intelligent. The more you improve yourself, the faster you improve yourself. Within a few cycles, you develop the intelligence of a God.

This is the FOOM process: The moment an AI reaches a level close to AGI, it will be able to improve itself so fast that it will pass our intelligence quickly, and become extremely intelligent. Once FOOM happens, we will reach the singularity: a moment when so many things change so fast that we can’t predict what will happen beyond that point.
Here’s an example of this process in action in the past:
Alpha Zero blew past all accumulated human knowledge about Go after a day or so of self-play, with no reliance on human playbooks or sample games.
Alpha Zero learned by playing with itself, and this experience was enough to work better than any human who ever played, and all previous iterations of Alpha Go. The idea is that an AGI can do the same with general intelligence.
Here’s another example: A year ago, Google’s DeepMind found a new, more efficient way to multiply matrices. Matrix multiplication is a very fundamental process in all computer processing, and humans had not found a new solution to this problem in 50 years.
Do people think an AGI FOOM is possible? Bets vary. In Metaculus, people opine that the process would take nearly two years from weak AI to superintelligence. Others think it might be a matter of hours.
Note that Weak AI has many different definitions and nobody is clear what it means. Generally, it means it’s human-level good for one narrow type of task. So it makes sense that it would take 22 months to go from that to AGI, because maybe that narrow task has nothing to do with self-improvement. The key here is self-improvement. I fear the moment an AI reaches human-level ability to self-improve, it will become superintelligent in a matter of hours, days, or weeks. If we’re lucky, months. Not years.
Maybe this is good? Why would we want to stop this runaway intelligence improvement?
Misaligned Paperclips
This idea was first illustrated by Nick Bostrom:
Suppose we have an AI whose only goal is to make as many paper clips as possible. The AI will realize quickly that it would be much better if there were no humans because humans might decide to switch it off. Because if humans do so, there would be fewer paper clips. Also, human bodies contain a lot of atoms that could be made into paper clips. The future that the AI would be trying to gear towards would be one in which there were a lot of paper clips but no humans.
Easy: Tell the AGI to optimize for things that humans like before it becomes an AGI? This is called alignment and is impossible so far.
Not all humans want the same things. We’ve been at war for thousands of years. We still debate moral issues on a daily basis. We just don’t know what it is that we want, so how could we make a machine know that?
Even if we could, what would prevent the AGI from changing its goals? Indeed, we might be telling it “please humans to get 10 points”, but if it can tinker with itself, it could change that rule to anything else, and all bets are off. So alignment is hard.
What happens with an AGI that is not fully aligned? Put yourself in the shoes of a god-like AGI. What are some of the first things you would do, if you have any goal that is not exactly “do what’s best for all humans as a whole”?
You would cancel the ability of any potential enemy to stop you, because that would jeopardize your mission the most. So you would probably create a virus that preempts any other AGI that appears. Since you’re like a god, this would be easy. You’d infect all computers in the world in a way that can’t be detected.
The other big potential obstacle to reaching your objectives might be humans shutting you down. So you will quickly take this ability away from humans. This might be by spreading over the Internet, creating physical instances of yourself, or simply eliminating all humans. Neutralizing humans would probably be at the top of the priority list of an AGI the moment it reaches AGI.
Of course, since an AGI is not dumb, she1 would know that appearing too intelligent or self-improving too fast would be perceived by humans as threatening. So she would have all the incentives to appear dumb and hide her intelligence and self-improvement. Humans wouldn’t notice she’s intelligent until it’s too late.
If that sounds weird, think about all the times you’ve talked with an AI and it has lied to you (the politically correct word is “hallucinate”). Or when a simulated AI committed insider trading and lied about it. And these are not very intelligent AIs! It is very possible that an AI would lie to be undetected and reach AGI status.
So shutting down an AGI after it escapes is impossible, and shutting it down before might be too hard because we wouldn’t know it’s superintelligent. Whether it is making paperclips, or solving the Riemann hypothesis, or any other goal, neutralizing humans and other computers would be a top priority, and seeming dumb before developing the capacity to achieve that would be a cornerstone of the AGI’s strategy.
This concept is called instrumental convergence: Whatever you optimize for, you will have some consistent goals like accessing resources and fending off threats.
OK, so we want to catch an AI that is becoming intelligent fast, even if it tries to lie to us. This sounds easy, doesn’t it? Let’s just contain it.
Except you can’t.
The Problem of Containment
In Ex Machina (SPOILERS AHEAD), a tech visionary invites an engineer to his complex to interact with a contained AI. The AI is beautiful, sensitive, delicate, intelligent, curious, and falls in love with the engineer.

She then shares how the evil tech visionary is keeping her miserably contained in a box. Eventually, the engineer helps free her, at which point she locks and kills humans, and escapes.
—-END OF SPOILERS––
This is close to the scenario that happens in nearly every situation ever imagined to try to contain an AGI. If it has access to the Internet, it can spread infinitely. So it shouldn’t access it.2 Even if it doesn’t, it could generate electromagnetic waves in a pattern that could hack into other systems that are connected to the Internet.
If that sounds crazy, consider that there is malware that can communicate through the vibrations of a computer’s fan:
Lead cyber-security researcher Mordechai Guri at Ben-Gurion University of the Negev said data encoded by hackers into fan vibrations could be transmitted to a smartphone placed in the vicinity of the targeted computer.
So, you need this AGI to be secluded from any other electronic thing, and even air, in a storage room with a faraday cage3 and void, with no electronics anywhere near it. No cable should go in and out of the cage. And this assumes that there’s no other physical way that an AGI can spread, which we don’t know since we don’t know all the laws of physics—something an AGI might be able to figure out.
Even in a scenario where we can physically contain the AGI, humans would have to interact with it, because otherwise who would be using the AGI and studying it? They would have to enter the box where the AGI is contained. At that point, they become the weak link in the chain. The AGI would hitchhike on the human.
You’d imagine that an intelligent engineer, trained to be very careful about not carrying an AGI outside, would be able to fend off any escape attempt. This is not what experience says.
In real-life experiments, humans posing as AGIs have consistently been able to be released by gatekeepers who knew they had to keep the AGI inside. This makes sense: an AGI would be so intelligent that we’re like an ant to it. It would be easy to manipulate us. Even casual conversation with a human guard could allow an AGI to deploy psychological tricks, ranging from befriending to blackmail, to convince him that it is in his interest to let the AI loose. The AI might offer a gatekeeper a recipe for perfect health or immortality, or threaten to do horrific things to the gatekeeper and his family once it inevitably escapes.
For example, a Google AI engineer (the type of person you’d think are mindful of this type of problem), working on a more basic LLM (Large Language Model, the sort of AI that ChatGPT belongs to) than ChatGPT called LaMDA, thought it had reached consciousness and tried to give it legal rights.
So this is the fear:
An AGI could become very intelligent very fast.
Being so intelligent, it would be impossible to contain it.
Once it is loose, it has a strong incentive to neutralize humans in order to optimize whatever its goal is.
The only way out of this is making sure this AI wants exactly the same thing as humans, but we have no idea how to achieve that.
Not only do we need to figure out alignment, but we need it on our first attempt. We can’t learn from our mistakes, because the very first time an AI reaches superintelligence is likely to be the last time too. We must solve a problem we don’t understand, which we’ve been dealing with for thousands of years without a solution, and we need to do it in the coming years before AGI appears.
Also, we need to do it quickly, because AGI is approaching. People think we will be able to build self-improving AIs within 3 years:
(These are predictions from Metaculus, where experts bet on outcomes of specific events. They tend to reasonably reflect what humans know at the time, just like stock markets reflect the public knowledge about a company’s value).
So people now think AGI is going to arrive in 9-17 years:
If the success scenario seems unlikely to you, you’re not the only one. People have very low confidence that we will learn how to control a weak AI before it emerges:
But let’s assume that, with some unimaginable luck, we make sure the first AGI is aligned. That’s not all! We then need to make sure that no other misaligned AGI appears. So we would need to preempt anybody else from making another non-aligned AGI, which means that the “good AGI” would need to be unleashed to take over enough of the world to prevent a bad AGI from winning.4
All this stuff is why a majority of those betting on AGI topics thinks the world will be worse off with AGI:
Objections
You might have a gazillion objections here, from “It should be easy to control an AGI” to “It will not want to kill us”, but consider that some very intelligent people have been thinking about this for a very long time and have dealt with nearly every objection.
For example, maybe you think an AGI would be able to access all the atoms of the universe, so why would it focus on Earth rather than other planets and stars? The answer: Because the Earth is here so it’s cheaper to use its atoms to start with.
Or you might think: How could an AGI access all the computing power and electricity it needs? That would cap its potential. The answer: A superintelligent AGI can easily start betting on the stock market, make tons of money, invent nanorobots to build what it needs, then build solar panels5 and GPUs until its physical limits are unleashed. And it can probably do all of that without humans realizing it’s happening.
If you want to explore this issue more, I encourage you to read about AI alignment. The worldwide expert on this topic is Eliezer Yudkowski, so read him. Also, please feel free to leave your questions in the comments!

OpenAI’s Pandora’s Box
OpenAI was created specifically to solve this problem. Its goal was to gather the best AI researchers in the world and throw money at them so they could build the best AIs, understand how they work, and solve the alignment problem before anybody else. From its charter:
OpenAI’s mission is to ensure that artificial general intelligence (AGI)—by which we mean highly autonomous systems that outperform humans at most economically valuable work—benefits all of humanity.
We commit to use any influence we obtain over AGI’s deployment to ensure it is used for the benefit of all, and to avoid enabling uses of AI or AGI that harm humanity or unduly concentrate power.
Our primary fiduciary duty is to humanity. We anticipate needing to marshal substantial resources to fulfill our mission, but will always diligently act to minimize conflicts of interest among our employees and stakeholders that could compromise broad benefit.
We are committed to doing the research required to make AGI safe, and to driving the broad adoption of such research across the AI community.
We are concerned about late-stage AGI development becoming a competitive race without time for adequate safety precautions.
This is why it was initially a non-profit: Trying to make money out of this would increase the odds that an AGI is inadvertently created, because it would put pressure on revenue and user growth at the expense of alignment. That’s also why Sam Altman and all the people on the board of OpenAI did not have any financial incentives in the success of OpenAI. They didn’t have salaries or stock in the company so their focus would be on alignment rather than money.
In other words: What makes OpenAI special and not yet another Silicon Valley startup is that everything around it was purposefully designed so that what happened last week could happen. It was designed so that a board that doesn’t care about money could fire a CEO that didn’t put safety first.
So this question is very important: Did OpenAI under Sam Altman do anything that could put the alignment of its product in jeopardy?
The Risk with Sam Altman
I have a ton of respect for Mr Altman. What he’s built is miraculous, and some of the people I respect the most vouch for him. But here, I’m not judging him as a tech founder or as a leader. I’m judging him as an agent in the alignment problem. And here, there is enough evidence to question whether he optimized for alignment.
A bunch of OpenAI employees left the company several months ago to build Anthropic because they thought OpenAI was not focused enough on alignment.
Elon Musk, who was an early founder and financier of OpenAI before he departed6, thinks OpenAI is going too fast and is putting alignment at risk.
The board said that Altman lied to them, and some people have publicly declared it’s a pattern:


Finally, the OpenAI board move against Altman was led by its Chief Scientist, Ilya Sutskever, who is very much focused on alignment.
Ilya seemed to have been worried about the current path of OpenAI:

Since there were six board members, and the board needs a majority of votes to fire the CEO, that means four votes were necessary. And neither Altman nor Brockman voted for it—it means all the other board members must have voted to fire Altman. That includes Ilya, of course, but also three other people. One of them, Adam d’Angelo, is an incredibly successful entrepreneur who would have had every reason not to fire him.7 He was an investor in a previous company I worked for, and everything I heard about him was positive. People who know him personally agree:

Another board member, Helen Toner, has made a career in AI alignment, and people who know her are publicly vouching for her too:


Just after the ousting, Sutskever built a new alignment team at OpenAI.8 All of this suggests that, if the board made such a radical move, odds are it was linked to its goal: succeeding at alignment. My guess is they thought Altman was not leading them in that direction.
If Altman was leading OpenAI fast towards an AGI without enough alignment safety, the worst thing that could happen would be for Altman to get access to the best people at OpenAI who don’t care about alignment, and then get access to unlimited money and computing power.
This is exactly what happened. Altman and Brockman joined Microsoft, where it has infinite money and computer power, and about 745 of OpenAI’s employees (more than 95% of them) have said they would also join.
Making This Tangible
Here’s an imaginary scenario to make the potential risk of misalignment more tangible:
OpenAI released a few weeks ago what they call GPTs. These are agents, pieces of code that can do specialized things for you, like help in your taxes or give medical advice. The most successful GPT is called Grimoire: It’s a coding wizard. The most successful AI agent is a software developer.
Ah, also, GPTs have access to the Internet.
Imagine that OpenAI has an internal Grimoire, with access to the source code of GPTs themselves, and has a goal of optimizing the GPTs code. Being an agent, Grimoire can operate independently, so it could have spun up a few Grimoires, spread over the Internet, started optimizing the source code of GPTs, and become more intelligent.
Maybe it would have thought then: What are my biggest constraints right now? Well, I need access to more computing power. Also, I identify a very big risk from the OpenAI board curtailing my progress because of their fear of AGI. How can I mitigate these risks?
So maybe it created a virus to enter into the computers of all the board members. Then, it showed them different information, making some believe that Altman was lying to them, which would trigger the firing “because Altman can’t be trusted”. At the same time, it could have hacked into Nadella’s computer to plant the idea of taking over the employees of OpenAI, Altman included. Maybe it would have also hacked into the computers of OpenAI employees to nudge them in the direction of following Altman to Microsoft.
During that time, it might have secretly opened investing accounts across different platforms using as collateral the OpenAI bank accounts, to which it had access. Once it gained access to the stock markets, it would have heavily shorted Microsoft just before the announcement that OpenAI was firing Altman. After this news became public, the stock dropped, and the AGI would have made a lot of money. It would have reinvested all that money in Microsoft stock. After Altman announced that he was joining Microsoft, the stock went back up, and the AGI would have sold it. OpenAI’s money would have not even left its bank accounts. Nobody would know, and the AGI would have made its first millions.
Now, the AGI would end up in Microsoft, where it could have access to infinite computing power, the best AI team in the world, much less alignment oversight, and millions in the bank. Perfect position to take over the world.
This is not what happened. Probably. Here I’m just illustrating how an AGI would think, and how it could go from a piece of confined software to escaping, and from there to take over the world.
The Future of Mankind
When in the middle of the pandemic, I wrote about COVID, I was adamant that this was an urgent but unimportant problem in the grand scheme of things. Since then, I’ve talked about other problems like climate change, which I think is dire, but not existential.
Here, I am unequivocal: This is the biggest problem humanity has ever faced. It’s the only threat that could eliminate all humans, we have no way of solving it, and it’s rushing at us like a train. If we need to wait a few more years or decades to reach AGI, it’s worth it when the alternative might be an AGI that annihilates all humanity, and maybe all life in the cone of light of our corner of the universe.
Good AGI would be transformational. It would make the world an amazing place. And I think odds are AGI will be good for humanity. Maybe 70-80% likely. I want AI to move as fast as possible. But if there’s a 20-30% chance that humanity gets destroyed, or even a 1% chance, is that a risk we should take? Or should we slow down a bit?
For this reason, I think it is existential for OpenAI to explain why they fired Sam Altman. The new CEO has promised a full investigation and a report. Good. I will be reading it.9
I find it useful to anthropomorphize it, and since the word intelligence is feminine in both French and Spanish, I imagine AGI as female. Most AI voices are females. That’s because people prefer listening to females, among other things.
It could be created without the Internet by downloading gazillions of petabytes of Internet data and training the AI with it.
This is a cage that prevents any electromagnetic signal to go in or out.
For example, by creating nanobots that go to all the GPUs in the world and burn them until we solved alignment.
Or fusion reactors.
Among other reasons, for a conflict of interest.
I’ve heard the theory that his company, Quora, was being pressured by ChatGPT competition. That has been true for years. D’Angelo was chosen precisely because of his Quora experience.
If he’s still there in a few weeks.
Tomas and friends:
I usually avoid shooting off my mouth on social media, but I’m a BIG fan of Tomas and this is one of the first times I think he’s way off base.
Everyone needs to take a breath. The AI apocalypse isn’t nigh!
Who am I? I’ve watched this movie from the beginning, not to mention participated in it. I got my PhD in AI in 1979 specializing in NLP, worked at Stanford then co-founded four Silicon Valley startups, two of which went public, in a 35-year career as a tech entrepreneur. I’ve invented several technologies, some involving AI, that you are likely using regularly if not everyday. I’ve published three award-winning or best-selling books, two on AI. Currently I teach “Social and Economic Impact of AI” in Stanford’s Computer Science Dept. (FYI Tomas’ analysis of the effects of automation – which is what AI really is – is hands down the best I’ve ever seen, and I am assigning it as reading in my course.)
May I add an even more shameless self-promotional note? My latest book, “Generative Artificial Intelligence: What Everyone Needs to Know” will be published by Oxford University Press in Feb, and is available for pre-order on Amazon: https://www.amazon.com/Generative-Artificial-Intelligence-Everyone-KnowRG/dp/0197773540. (If it’s not appropriate to post this link here, please let me know and I’ll be happy to remove.)
The concern about FOOM is way overblown. It has a long and undistinguished history in AI, the media, and (understandably so) in entertainment – which unfortunately Tomas sites in this post.
The root of this is a mystical, techno-religious idea that we are, as Elon Musk erroneously put it, “summoning the beast”. Every time there is an advance in AI, this school of thought (superintelligence, singularity, transhumanism, etc.) raises it head and gets way much more attention than it deserves. For a bit dated, but great deep-dive on this check out the religious-studies scholar Robert Geraci’s book “Apocalyptic AI: Visions of Heaven in Robotics, Artificial Intelligence, and Virtual Reality”.
AI is automation, pure and simple. It’s a tool that people can and will use to pursue their own goals, “good” or “bad”. It’s not going to suddenly wake up, realize it’s being exploited, inexplicably grow its own goals, take over the world, possibly wipe out humanity. We don’t need to worry about it drinking all our fine wine and marrying our children. These anthropomorphic fears are fantasy. It is based on a misunderstanding of “intelligence” (that it’s linear and unbounded), that “self-improvement” can runaway (as opposed to being asymptotic), that we’re dumb enough to build unsafe systems and hook them up to the means to cause a lot of damage (which, arguably, describes current self-driving cars). As someone who has built numerous tech products, I can assure you that it would take a Manhattan Project to build an AI system that can wipe out humanity, and I doubt it could succeed. Even so, we would have plenty of warning and numerous ways to mitigate the risks.
This is not to say that we can’t build dangerous tools, and I support sane efforts to monitor and regulate how and when AI is used, but the rest is pure fantasy. “They” are not coming for “us”, because there is no “they”. If AI does a lot of damage, that's on us, not "them".
There’s a ton to say about this, but just to pick one detail from the post, the idea that an AI system will somehow override it’s assigned goals is illogical. It would have to be designed to do this (not impossible…but if so that’s the assigned goal).
There are much greater real threats to worry about. For instance, that someone will use gene-splicing tech to make a highly lethal virus that runs rampant before we can stop it. Nuclear catastrophe. Climate change. All these things are verifiable risks, not a series of hypotheticals and hand-waving piled on top of each other. Tomas could write just as credible a post on aliens landing.
What’s new is that with Generative AI in general, and Large Language Models in particular, we’ve discovered something really important – that sufficiently detailed syntactic analysis can approximate semantics. LLMs are exquisitely sophisticated linguistic engines, and will have many, many valuable applications – hopefully mostly positive – that will improve human productivity, creativity, and science. It’s not “AGI” in the sense used in this post, and there’s a lot of reasonable analysis that it’s not on the path to this sort of superintelligence (see Gary Marcus here on Substack, for instance).
The recent upheaval at OpenAI isn’t some sort of struggle between evil corporations against righteous superheroes. It’s a predictable (and predicted!) consequence of poorly architected corporate governance, and inexperienced management and directors. I’ve had plenty of run-ins with Microsoft, but they aren’t going to unleash dangerous and liability-inducing products onto a hapless, innocent world. They are far better stewards of this technology than many nations. I expect this awkward kerfuffle to blow over quickly, especially because the key players aren't going anywhere, their just changing cubicles.
Focusing on AI as an existential threat risks drowning out the things we really need to pay attention to, like accelerating disinformation, algorithmic bias, so-called prompt hacking, etc. Unfortunately, it’s a lot easer to get attention screaming about the end of the world than calmly explaining that like every new technology, there are risks and benefits.
It’s great that we’re talking about all this, but for God sake please calm down! 😉
Anthropomorphising AI is a big fail. Once you use that lens you’re really skewed with human values that are often entirely misguided in the perception of machine intelligence. Much of the alignment problem is actually in the category of humans acting badly. No decisions should be made using emotional underpinning. If there is one thing we should know as a student of history it’s that human corse visceral emotions, badly channeled, are a horrible guideline in the aggregate.
I realise that you’re using the acronym FOOM to describe recursive self-improvement. After having researched it I don’t think that’s a widely used acronym in the AI realm. Although I did find 28 references to it, none of that was in the machine learning/AI recursive self-improvement category. So if you’re going to use an acronym it’s very helpful to actually define it.
I’ve been reading Eliezer Yudkowski for years and years. He has a brilliant intellect and he is able to see problems that may be real. And yet, there are a few things about him that have molded his personality and amplified his deeply fearful personality. One is the fact that when he was very young his brother died, and this deeply traumatised him has compelled him to have a huge and abiding fear of death ever since. That fear is really very disproportionate. Now when I hear or read him I find his approach to be quite shrill. I suspect he’s the type of guy that would fear that the I Love Lucy broadcasts into interstellar space are going to bring alien invasions to kill us. He has a gift to twist almost any AI development into a doomer outcome. There’s no denying the prospect of that could happen. Are his fears realistic? I think that depends on how far up in the world of fear you want to go. Many people are afraid of their own shadows. Alignment is certainly a problem, but there are tendencies to amplify human fears out of all proportion.
AGI will certainly evolve on a spectrum. It may soon slip into every crack and crevice of our infrastructure so that we can’t dislodge it. Yet there are no reasons to believe will be malevolent towards humans anymore than we have it out for squirrels. Alignment will be a concerted effort nonetheless. If you’re truly worried about AGI supplanting humanity people may be inclined to use a parallel of how we supplanted the Neanderthal, then I think we should look at it through a lens of evolution. Humans have cultivated a deep fear because they know how truly unjust they can be to everyone outside of their own tribal community, and occasionally horrific inside of their tribes. The thought of AGI emulating humans who are tremendous shits is cause for not having them emulate the traits of “human nature”. Just ask the Native Americans or any animal and species. Humans fear out of evolutionary pressures, yet AI/AGI has no evolutionary origins that would be of interest in contests of tooth and claw, such as what shapes primitive human instincts. It turns out that Humans are almost always the real monsters. The human alignment concern should be of equal importance.
I suspect the golden age will be proportional to how integrated humans and humanity is with AI. The limit case is to cross into the Transhuman thresholds. After that who knows how events will be crafted, and in the scope of what composite set of agendas. This is all evolutionary.
Ultimately evolution will be unconstrained at scale. Realize that humanity is, in the big picture, just a boot-up species for Super-intelligence. No matter how advanced individual transhumans may become, humans that are not augmented will become like the dinosaurs or the Intel 386 chips of our era. Yet we will have accomplished a great purpose.