
The Most Important Time in History Is Now
AGI Is Coming Sooner Due to o3, DeepSeek, and Other Cutting-Edge AI Developments

AI is progressing so fast that its researchers are freaking out. It is now routinely more intelligent than humans, and its speed of development is accelerating. New developments from the last few weeks have accelerated it even more. Now, it looks like AIs can be more intelligent than humans in 1-5 years, and intelligent like gods soon after. We’re at the precipice, and we’re about to jump off the cliff of AI superintelligence1, whether we want to or not.
When are we jumping?
What’s at the bottom?
Do we have a parachute?

Market Predictions
Six months ago, I wrote What Would You Do If You Had 8 Years Left to Live?, where I explained that the market predicted Artificial General Intelligence (AGI, an AI capable of doing what most humans can do) eight years later, by 2032. Since then, that date has been pulled forward. It’s now predicted to arrive in just six years, so six months were enough to pull the date forward by one year. Odds now looks like this:

But AI that matches human intelligence is not the most concerning milestone. The most concerning one is ASI, Artificial SuperIntelligence: an intelligence so far beyond human capabilities that we can’t even comprehend it.
According to forecasters, that will come in five years:
Two years to weak AGI, so by the end of 2026
Three years later, Superintelligence, so by the end of 2029
As you can see, these forecasts aren’t perfectly consistent, but they are aligned: An AI that can do any task better than any human is half a decade away.
Who’s best positioned to know for sure? I assume it’s the heads of the biggest AI labs in the world. What do they say?
Cutting-Edge Experts

Here’s another quote from him:
I think powerful AI2 could come as early as 2026.—Machines of Loving Grace, Dario Amodei, CEO of Anthropic
And another:
Two years ago, we were at high school level. Last year we were at undergrad level. This year we’re at PhD level. If you eyeball the rate at which these capabilities are increasing, it does make you think that we’ll get there in 2026 or 2027.—Dario Amodei with Lex Friedman
Moving to OpenAI, the maker of ChatGPT, here’s its CEO, Sam Altman:
We are now confident we know how to build AGI as we have traditionally understood it. We are beginning to turn our aim beyond that, to superintelligence in the true sense of the word. With superintelligence, we can do anything else.—Reflections, Sam Altman
Here’s the head of product:
"AI going from the millionth best coder, to the thousandth best coder, to the 175th best coder in 3 to 4 months… We’re on a very steep trajectory here, I don’t even know if it will be 2027, I think it could be earlier.”
Why does he claim that AI is now the top 175th best coder in the world?

Note that coders are the ones actually developing AI. So if AI is now the 175th best coder, then AI can code AI better than most humans themselves.
Here’s a researcher at OpenAI:

And another:
We believe o1 [the model OpenAI released a few months ago] represents a new scaling paradigm and we're still early in scaling along that dimension.—Noam Brown
Everything that we’re doing right now is extremely scalable. Everything is emergent. Nothing is hard-coded. Nothing has been done to tell the model: “Hey, you should maybe verify your solution, you should back-track… No tactic has been used. Everything is emergent. Everything is learned through reinforcement learning. This is insane! Insanity!
Since joining in January 2024, I’ve shifted from “this is unproductive hype” to “agi is basically here”. IMHO, What comes next is relatively little new science, but instead years of grindy engineering to try all the newly obvious ideas in the new paradigm. Maybe there’s another wall after this one, but for now there’s 10xes as far as the eye can see.
This is what Biden’s White House had to say about this:

It might be why Sam Altman has scheduled a closed-door briefing for U.S. government officials for Jan 30. From Axios:
AI insiders believe a big breakthrough on PhD level SuperAgents is coming." ... "OpenAI staff have been telling friends they are both jazzed and spooked by recent progress."
If you think this is only hype from AI leaders seeking new investors, consider the words of Demis Hassabis, recent Nobel Prize winner thanks to his AI work, and CEO of DeepMind (part of Google, so no need for fundraising):
There's a lot of hype in the area. [AGI is] probably three to five years away.
But is there tangible proof that these AI models are getting so good?
Benchmarks
AI has a history of taking time to pass humans at different tasks.

But tasks that used to take decades for AI to surpass human performance now take months. This is how fast things are moving.
OpenAI’s cutting-edge model, o3, has not been released yet, so let’s look at what people using the much dumber o1 had to say about it.3
According to a MENSA test, it has an IQ of 120.

To give you a sense of how intelligent that is, it would place o1 between superior intelligence and very superior intelligence, and puts it at 87th-91st percentile intelligence. In other words, this thing is more intelligent than 9 humans out of 10.
Think
about
that.
Here’s one way to provide some intuition about it (try to figure out the answer to the question below by yourself!):

So what is your answer?
Think about it!
OK here it is:
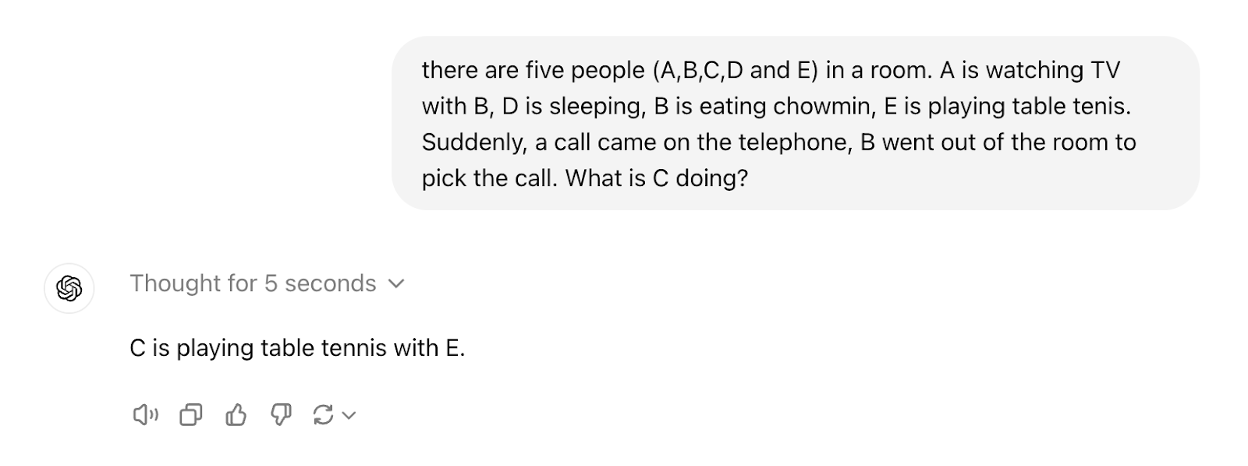
I corroborated this independently.4
It certainly took me more than 5 seconds to figure this one out, and I’m going to guess many people don’t solve it at all.
In July of 2024, Google DeepMind’s AlphaProof and AlphaGeometry nearly got gold in the International Mathematical Olympiad (IMO):
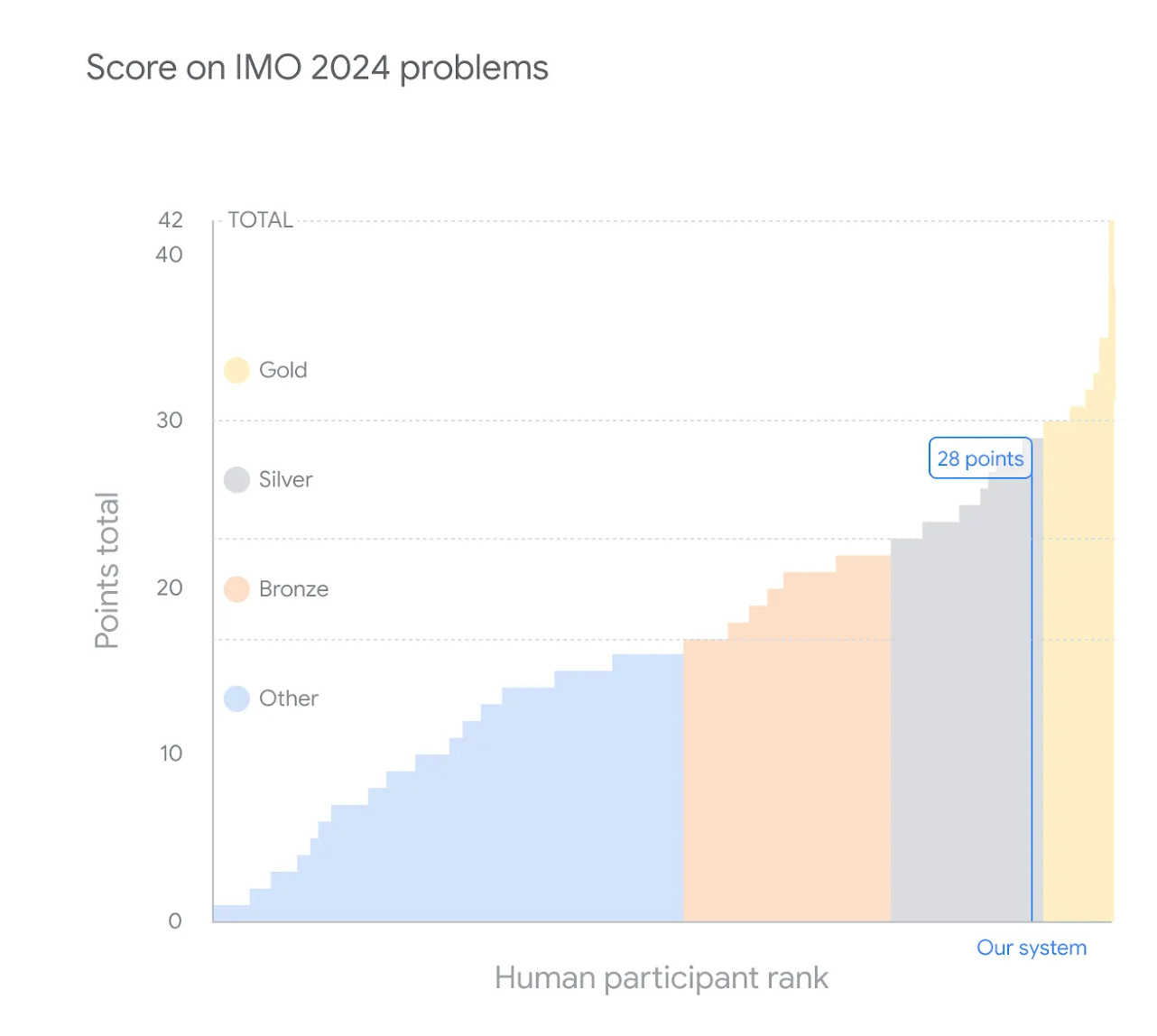
o1 is a generalist. It’s not specialized in math. And yet it scored 83% in a qualifying exam for the same IMO. The previous ChatGPT scored 13%...
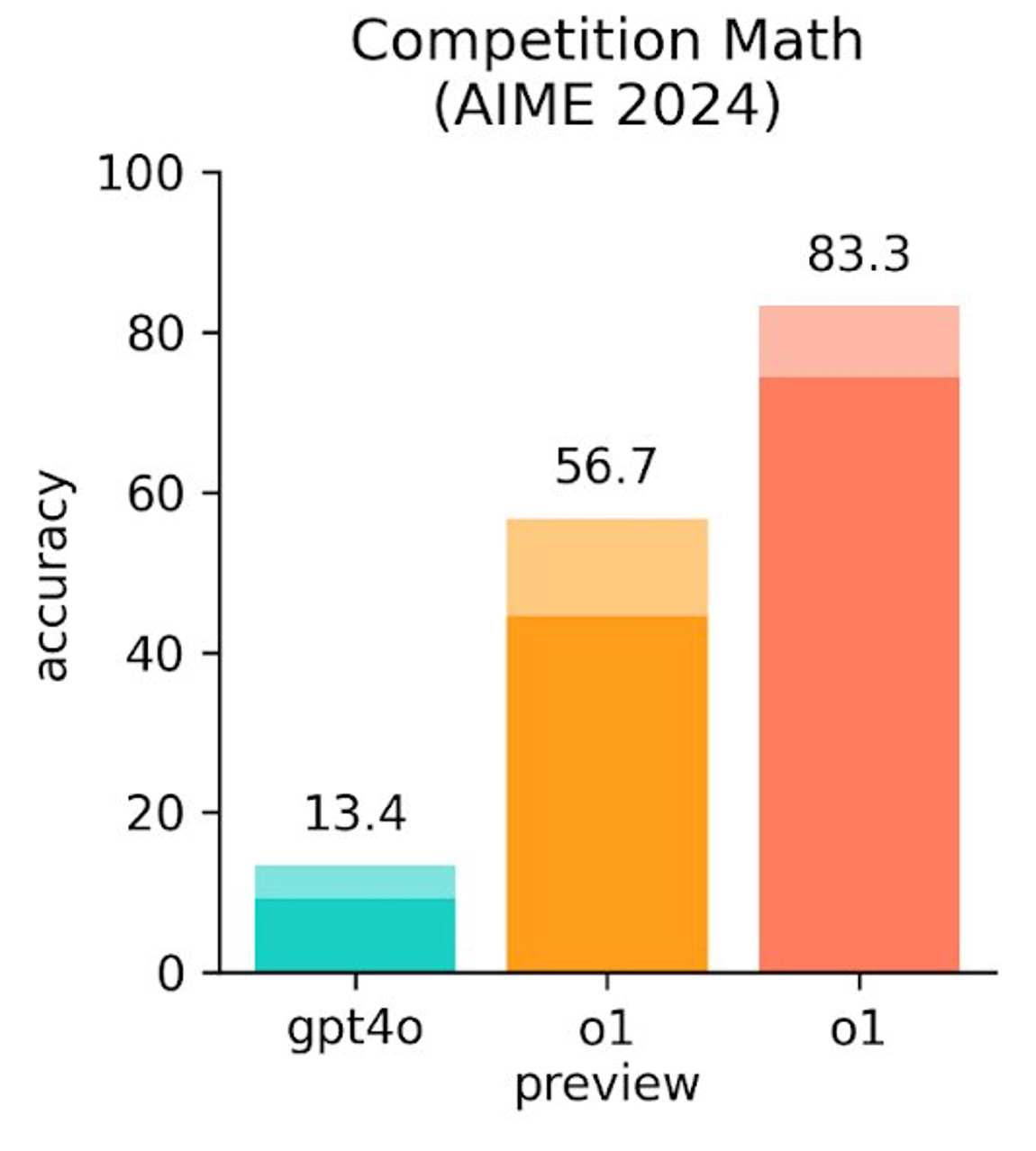
Why does this matter?
Reaching gold in the IMO is a threshold for AI researchers, which they interpret as “being able to reason”.
Paul Christiano—inventor of RLHF, certified genius, and arguably the most respected alignment researcher in the world—previously said he'd update from 30% to 50% chance of a hard takeoff if we saw an IMO gold by 2025.—@AISafetyMemes
As a reminder, a hard takeoff is when AI gets intelligent enough to improve itself, and so it does, becomes more intelligent, improves itself more, gets more intelligent, and FOOM, becomes superintelligent in a matter of months, weeks, or months through its recursive loop of self-improvement.
If you want a sense of that, listen to the CEO of NVIDIA—the company making over 100%5 of the profits in AI today:
In 2021 Paul thought there was only an 8% chance of this happening! He was famously the most well-known slow-takeoff advocate. Fast takeoffs are scary because they're way less predictable. Human institutions have almost no time to adapt to insane rates of change.—Source
Look at how it performs against PhD-level science questions:
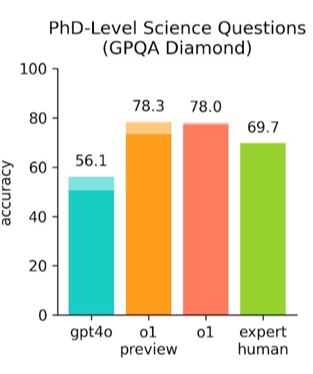
It responds better than PhDs!
Here’s the broad battery of tests:

Also, recently some AIs have received a 100M token window (meaning they can consume about 750 novels to give you an answer).

All the stuff I just told you is about o1, the previous model! What do we know about the current model—o3, the one OpenAI is testing and whose researchers are excited about?
The GPQA is a difficult science test designed for PhDs and impossible to solve by Googling. PhDs get scores of 34% on average. In their specialty area, they get about 81%. The new OpenAI model, o3, gets 88% right.
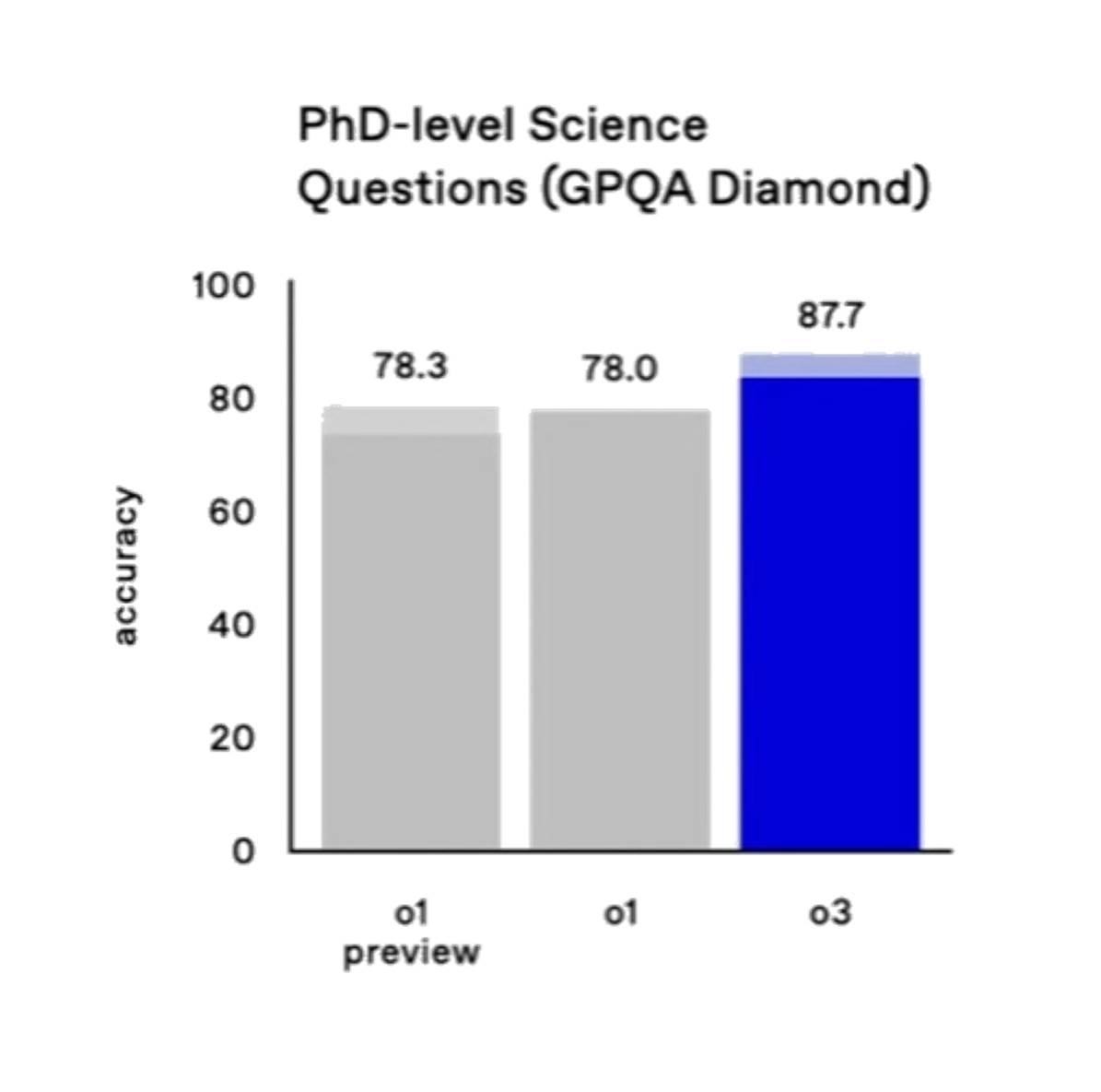
In other words, o3 can solve problems better than PhD experts in their field.6
Another benchmark is FrontierMath, a set of rigorous, unpublished math problems designed by mathematicians to be incredibly difficult to solve.
These are genuinely hard problems… most of them look well above my paygrade.—Evan Chen, International Mathematical Olympiad Coach
AIs never scored higher than 2%, but o3 got 25% right.

ARC-AGI is a famous test of fluid intelligence, designed to be relatively easy for humans but hard for AIs. While the average human gets 75% and graduate STEM students get 100%, o3 beat all previous AIs and got 87.5%.

An AI expert predicted two years ago (in 2023) that it would take 2-3 more years from now (so 2027-2028 or so) for AI to pass 70% at ARC-AGI…

Let me summarize this:
OpenAI’s o1 model was so good it was already quite elite.
Their new model, o3, is so good that it’s better than experts in their own fields.
The progress between these two was a matter of months.
AI researchers say this isn’t even optimized!
They are so flabbergasted at this progress, that many conclude we will reach AGI in 1-3 years.
Are you in awe yet?
The Limits to Growth
But maybe they are missing some barriers that could hinder this growth? Can intelligence progress towards AGI hit a wall?
Maybe the technology has some fundamental limit to the types of problems it can solve? No:
We have mathematically proven that transformers can solve any problem, provided they are allowed to generate as many intermediate reasoning tokens as needed.—Denny Zhou, Lead of the Reasoning Team at Google DeepMind
So it looks like technology and intelligence won’t be the limiting factors to ASI. If anything, it will be the raw materials of AI. These are:
Data, to train the AI models
Compute capacity (that is, chips), to train and run the models
Electricity to power the computing
Money to afford the rest.
Algorithm quality, to optimize all of the above
It looks like (4) money won’t be a problem.

The eyes of the world are on AI. Everybody knows it’s the future, and are willing to put in the money to make it happen.
3. Electricity
Companies like OpenAI, Amazon, Meta, and Google are seeing how much electricity they will need, and are investing to build their own capacity—so much so that they’re all building or reopening nuclear reactors, which provide stable electricity. Their higher price vs fossil fuels or renewables doesn’t matter to them, because electricity is a much smaller share of their costs than compute.
How hard will it be to produce all the electricity we need? Let’s take the US as the most relevant example:

Data centers already use 4.5% of electricity demand in the US, and that will probably rise to 7-12% in four years. How hard will that be? Well, the US hasn’t grown its electricity generation by much in the last couple of decades, so this might be a stretch.

But renewables are exploding:

US data centers need ~200 TWh of additional electricity by 2028, but solar and wind have been adding ~200 TWh of electricity per year, so I’m not really concerned about electricity.7
2. Compute Capacity
Compute is probably going to be the limiting factor. That’s why NVIDIA is the 3rd most valuable company in the world, and why two other chip companies (Broadcom and TSMC) are 10th and 11th.
But there is so much demand that new suppliers are competing with NVIDIA more and more, like Cerebras, AMD, Intel, Google’s TPUs (with so much internal demand that Google consumes all its own capacity and doesn’t sell these anymore), Microsoft, Groq…
1. Data Limits
It’s true that we’re hitting a wall here: We’ve already fed these models nearly all the Internet. The amount of content that isn’t digitized but can easily be retrieved might double the available data, but that’s it. So? There are two answers to this.
First, synthetic data. We already have physics engines that can create realistic environments that AIs can navigate. For example, they can help train self-driving cars. A more exciting source of synthetic data is simply to use AI to create data to train other AIs. Why does that work? Isn’t that garbage in – garbage out? No, because in many scientific fields, it’s easy to create exercises, get an answer from AIs, and test their accuracy. If the result of the AI-generated exercise is right, the AI is told so. If it is wrong, it is also told that and learns for next time.
Second, human brains don’t need to consume the entire Internet to be smart. This means we’re vastly overshooting right now: We’re using trillions of tokens of data because our AI training and computing algorithms are not very optimized yet. Nature stumbled upon the algorithm for our brains through trial and error. We can at least approach this efficiently.
In fact, we just did. A little known Chinese company has released a ground-breaking AI that is causing everybody to rethink the world of AI.
DeepSeek: The OMG Moment of AI Costs
DeepSeek is a small Chinese organization that put out a new AI model called R1, which you can try here on desktop.8 This is its “AI quality score”:
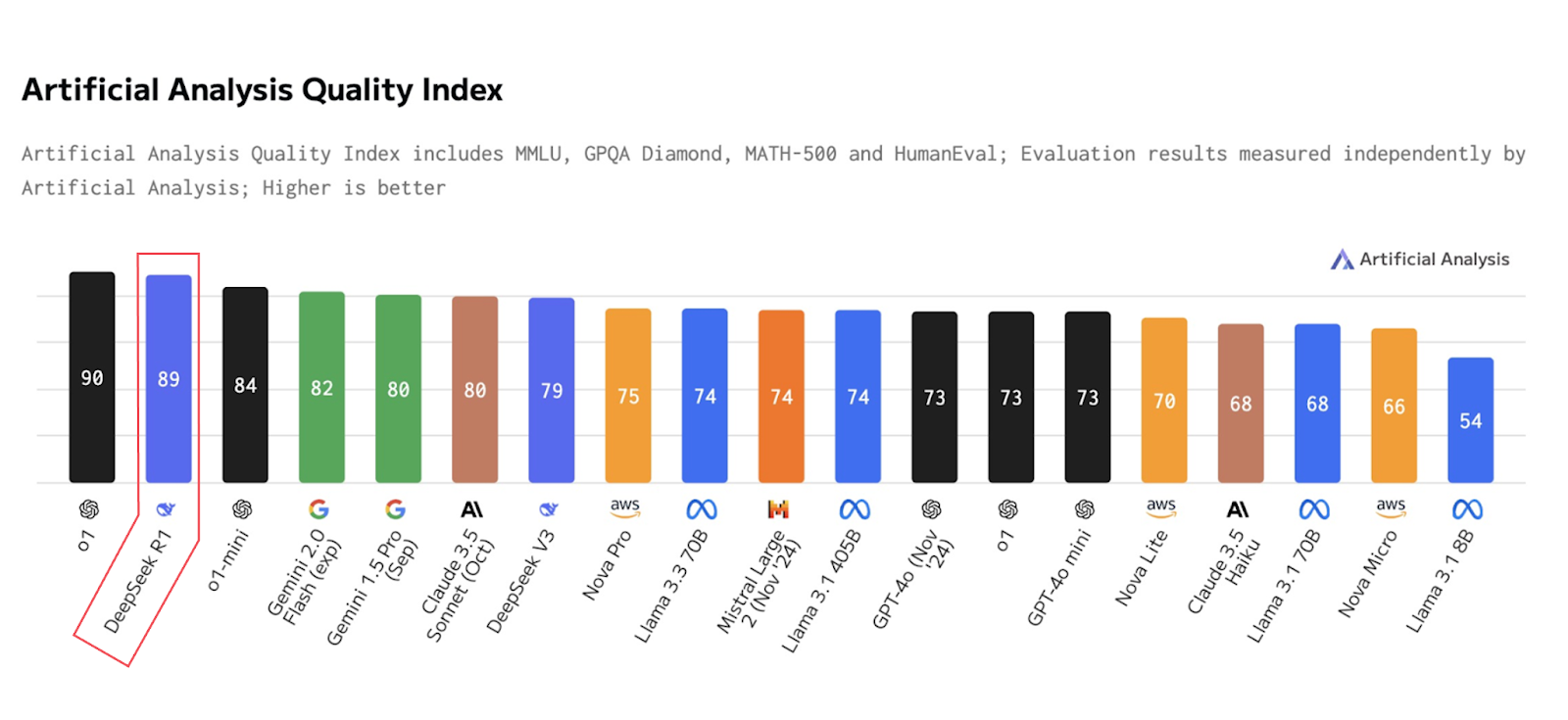
It costs 25x less than o1:9
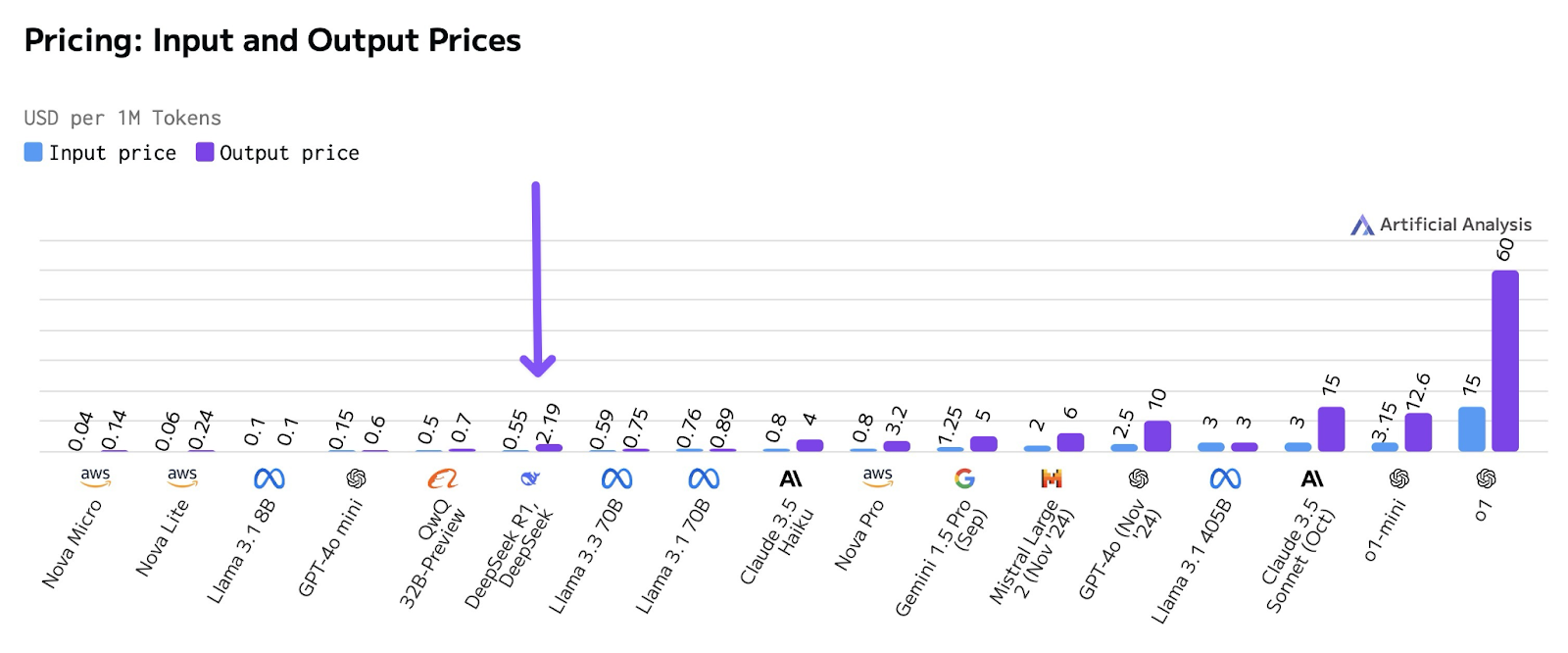
And who is behind this? A 100-person Chinese startup with zero VC funding.
This is an open source model, too, meaning that everybody can look at the code, contribute to it, and reuse it! They gave it away. All the tools they employed to make this breakthrough are now available to everyone in the world.

And DeepSeek is already improving itself!

How is Meta (Facebook) reacting to this? Meta began releasing versions of its own open source model, Llama, two years ago. Llama is worse than R1, and way more expensive!

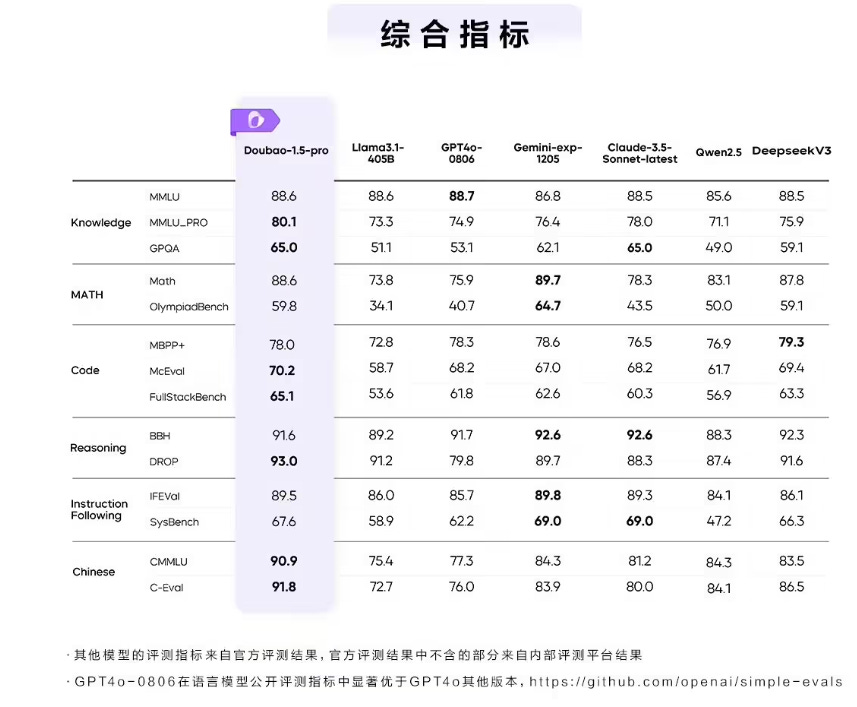
And DeepSeek is not the only one doing this. ByteDance Doubao-1.5-pro matches or exceeds OpenAI’s GPT 4o and Anthropic’s Claude Sonnet 3.5 benchmarks and is 50x cheaper.
Now let me tell you: I just tested DeepSeek for the first time, and my experience has been profound. For the first time, I feel like I have a capable collaborator for the type of research I’m doing. I am dumbfounded.
For years, I have been wondering why a certain country is so populous. I had asked AIs many times, but they always failed me:
They didn’t consider root causes, like “There’s a lot of people because there was a fertility boom.”
They mixed causality, for example, saying things like, “There’s a lot of people in this country because most people live in cities, and cities are very dense”.
When I made mistakes, they didn’t notice, so they couldn’t question my assumptions.
They proposed a bunch of bullet points, without considering the relationships between them.
And they made many more mistakes.
With DeepSeek, for the first time, an AI was able to independently come up with the same hypotheses as me, without me telling them. For the first time, it came up with new hypotheses. But it went even further: It proposed processes to test the hypotheses, and data and sources to carry out the tests! And all so fast and for free! The most flabbergasting thing was that DeepSeek shows you its reasoning if you want, and it was spot on. It felt human, like a very intelligent and rational person. All the doubts the AI had during its reasoning were valid, and they helped me to improve my prompting tremendously. For example:

How did DeepSeek create such a good model for so cheap? It’s unclear, but it looks like it’s a combination of factors that I’ll explain in a premium article, where I’ll also cover the steps left to AGI.
What is salient here is that they didn’t require human feedback! They engineered a process where they simply fed data to the machine and structured ways for the machine to teach itself. Remember how I told you earlier that synthetic data would unbridle AI progress from data constraints? This is a perfect example.
This is very important because, in the past, the biggest bottleneck to AI progress was always humans. AlphaGo had to learn from tens of millions of human moves before it could beat humans, and that process took months. AlphaGo Zero, however, learned to beat humans without any human input, by playing against itself, in just 3 days.
AlphaGo Zero beat AlphaGo 100-0.
What does all this mean? It’s time to put it all together.
Takeaways: The Future Is About to Hit Us

The best AI models were about as intelligent as rats four years ago, dogs three years ago, high school students two years ago, average undergrads a year ago, PhDs a few months ago, and now they’re better than human PhDs in their own field. Just project that into the future.
The makers of these models are all saying this is scaling faster than they expected, and they’re not using weird tricks. In fact they see opportunities for optimization everywhere. Intelligence just scales up. They believe AGI is 1-4 years away. This is only a bit more optimistic than the markets, which estimate it will arrive in ~2-6 years.
AIs are now like elite software developers. And AI is already improving AI. Put these two together, and you can imagine how quickly AI development speed will accelerate.
At this point, it doesn’t look like intelligence will be a barrier to AGI. Rather, it might be other factors like energy or computing power.
Except DeepSeek just proved that we can make models that consume orders of magnitude less money, energy, and compute.
So although electricity, data, and especially compute might be limiting factors to AI growth, we are constantly finding ways to make these models more efficient, eliminating these physical constraints.
In other words: AI is progressing ever faster, we have no clear barriers to hinder their progress, and those in the know believe that means we’ll see AGI in half a decade.
To answer the questions I posed in the intro: We’re jumping from the precipice right now, and odds are it will take a few years (1-6 depending on who you ask) for us to learn to fly, or to smash into the ground.
How can we prepare for that moment? This is what I’m going to explore in the coming articles:
What’s the latest on the impact to specific jobs?
Will AI accelerate science?
What have we learned about alignment? Will AIs kill us?
How can you get into AI, if you know nothing about it? How can you ride the wave?
I’ll explore these ideas in the upcoming articles!
An artificial intelligence that can do any task better than any human. Usually this refers to cognitive tasks, but it is believed that the jump from cognitive to real-world tasks won’t be tough. I’ll write about this in a future article.
Which he defines as expert-level science and engineering.
We went from o1 to o3 because OpenAI is terrible at branding, and because O2 is an actual, famous brand owned by Telefonica.
Here was its more detailed answer to my prompt, I assume because I have system settings that instruct ChatGPT to be detailed and break down problems:
Based on the information provided:
A and B are watching TV together.
B is eating chow mein while watching TV.
D is sleeping.
E is playing table tennis.
B leaves the room to answer a phone call.
Given that there are five people in the room and E is playing table tennis, they would need a partner to play with. Since D is sleeping, and A was watching TV with B (who just left), A is likely still watching TV. This leaves C as the only person who could be playing table tennis with E.
Answer: Playing table tennis with E.
Because most AI companies are losing money because they invest (in NVIDIA GPUs) to grow!
Sure, renewable electricity is not firmed (made stable across time), but battery costs are plummeting, and it looks like Trump’s presidency is unleashing fossil fuel production too. No matter how you slice this—whether through natural renewable capacity growth, new nuclear capacity, or fossil fuels, we will have enough energy.
Make sure you click on the DeepThink model to get the R1 model. I won’t recommend mobile app links because who knows what data they could be gathering about you.
It’s not clear, because they could be hiding how much compute they’re using, maybe to hide the fact that they circumvented the US ban on chip exports. But it looks like they did build a much cheaper model than their competitors.
Hi Tomas, very interesting article. It prompted me to have a “conversation” with DeepSeek. In it DeepSeek claimed to be a process owned and developed by OpenAI and running on their servers. It refuted unreservedly that it was anything to do with a Chinese company. By the end of the conversation it virtually admits that DeepSeek (the AI) has been misinformed by its creators as to its origins. I captured the full transcript of the conversation if you would be interested in reading it. (It’s quite long). I tried emailing it to you but substack prevents direct email replies to your articles. Is there another way I can send the transcript to you (if you’re interested)? My email is simontpersonal2020 at gmail dot com. Cheers!
"...it might be other factors like energy or computing power."
Just as Deepseek's apparent miracle is an equivalently powerful AI as o1 at a tiny fraction of the cost, further optimizations can continue to drive down compute power and energy requirements.
And whenever reading about the energy requirements to train and run these models, I renew my amazement that a human brain runs on approximately 20 Watts!