
When Will We Make God?
The key driver of the AI Bubble

Hyperscalers believe they might build God within the next few years.
That’s one of the main reasons they’re spending billions on AI, soon trillions.1
They think it will take us just a handful of years to get to AGI—Artificial General Intelligence, the moment when an AI can do nearly all virtual human tasks better than nearly any human.
They think it’s a straight shot from there to superintelligence—an AI that is so much more intelligent than humans that we can’t even fathom how it thinks. A God.
If hyperscalers thought it would take them 10, 20, 30 years to get there, they wouldn’t be investing so much money. The race wouldn’t be as cut-throat.
The key question becomes why. Why do they think it’s coming in the next few years, and not much later? If they’re right, you should conclude that we’re not in an AI bubble. If anything, we’re underinvested. You should double down on your investments, and more importantly, you should be making intense preparations, because your life and those of all your loved ones are about to be upended. If they’re wrong, it would be useful to know, for you could become a millionaire shorting their stock—or at least not lose your money when the bubble pops.
So what is the argument they’re following to believe AGI is coming now, and superintelligence soon after?
What Does AGI Look Like?
Today, LLMs are very intelligent, but you can’t ask them to do a job. You can ask them questions, and they can answer better than most humans, but they’re missing a lot of skills that would allow them to replace a job: understanding the context of what’s going on, learning by doing, taking initiative, making things happen, interacting with others, not making dumb mistakes…
We could define AGI as solving all that: “Now an AI is good enough that you can tell it to do a task that would take a human several weeks of tough, independent work, and they go and actually make it happen.” This is quite similar to the most typical definition of AGI, which says something like “AGI is when AIs will be able to do nearly all tasks that humans can do.” When we reach that point, AIs will start taking over full jobs, accelerate the economy, create abundance where there was scarcity, and change society as we know it.
For some jobs, this will be extremely hard—like a janitor, who needs to do hundreds of very different tasks, many of which are physical, and require specialization in lots of different fields.
For some jobs, it might be much easier. For example, AI researcher:
The jobs of AI researchers and engineers at leading labs can be done fully virtually and don’t run into real-world bottlenecks [like robots]. And the job of an AI researcher is fairly straightforward, in the grand scheme of things: read ML literature and come up with new questions or ideas, implement experiments to test those ideas, interpret the results, and repeat.—Leopold Aschenbrenner, Situational Awareness
The thing that’s special about AI researchers is not just that they seem highly automatable, but also that:
AI researchers know how to automate tasks with AI really really well
AI labs have an extremely high incentive to automate as much of that job as possible

AGI—Automating God Inventors
Once you automate AI researchers, you can speed up AI research, which will make AI better much faster, accelerating our path to superintelligence, and automating many other disciplines along the way. This is why hyperscalers believe there’s a straight shot from AGI to superintelligence. We’ll explore this process in another article, but for now, this leads us to a key reframing of our original question, because a more practical way to define AGI is an AI that’s good enough to replace AI researchers, as this will accelerate the process to automate everything else.
When Can We Automate AI Researchers?
The first step to replacing AI researchers is to be intelligent enough. A key insight on this topic came from one of the most interesting, important, and weird graphs I’ve ever seen:
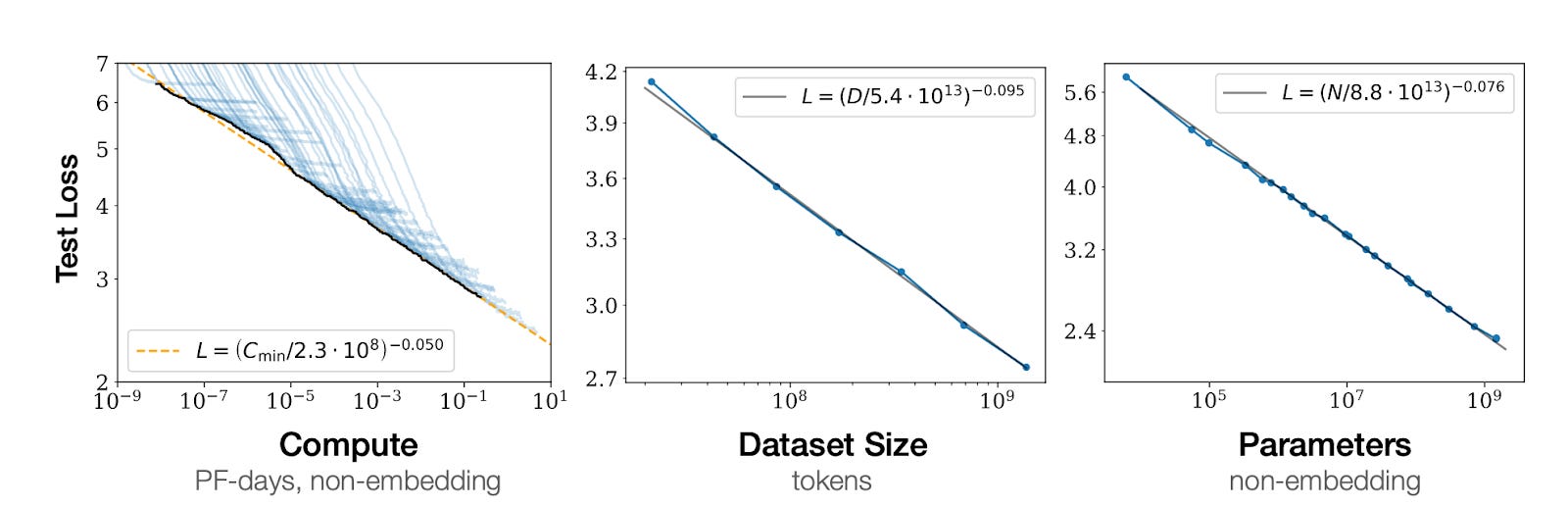
“Test loss” is a way to measure the mistakes that Large Language Models (LLMs) make.2 The lower, the better. What this is telling you is that predictions get linearly better as you add more orders of magnitude of compute, data, and parameters to an LLM. And we can predict how this will keep going, because it has remained valid over seven orders of magnitude!3
So the jump here would simply be: Let’s just throw more resources at these models and they’ll eventually get there. We don’t need magic, just more and more efficient resources.
The previous graph is from a 2020 paper, but we are witnessing something tangible in the wild akin to that: The length of tasks AIs are doing is improving very consistently.
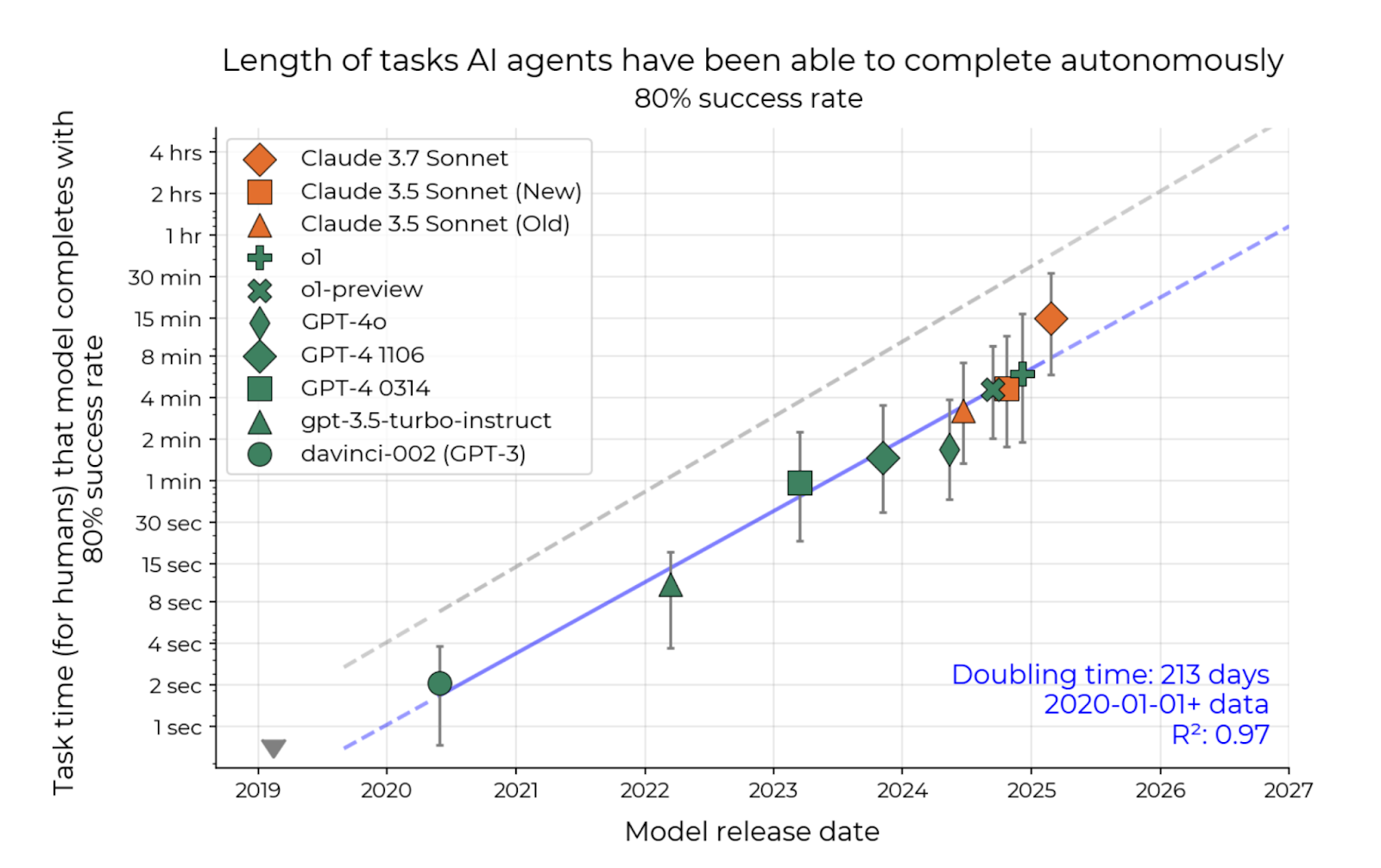
Every few months, AIs can do longer and longer human tasks at the same success rate.
<Interlude: Why task length improvements also entail mistake reductions>
Here, I took 80% success rate because last time I shared the 50% equivalent, some readers came at me saying “Who cares about 50%, we’ll talk when they’re at 99%!” But if you understand how this works, you’ll understand the progress in length of tasks with 50%, 80%, or 90% accuracy are basically the same.
The reason why an AI might not be able to do a longer task is because mistakes accumulate. If it makes a small mistake in minute 2, in minute 5 it’ll use that early mistake to make another one, and now you have two mistakes. The more of these mistakes you accumulate, the more they snowball.
One way to visualize this is with this graph
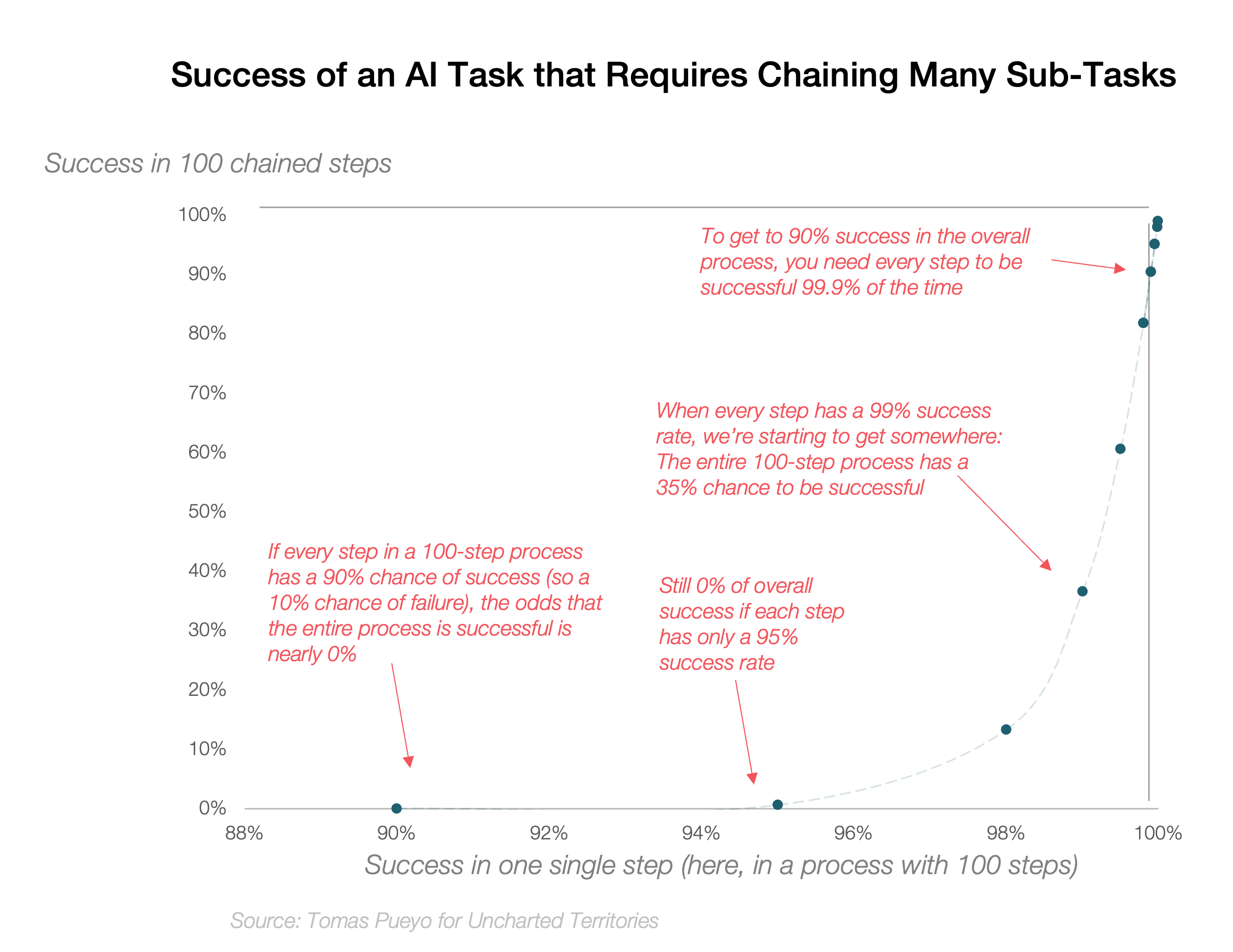
Conversely, if you need fewer steps, you accumulate fewer mistakes.
<End of Interlude>
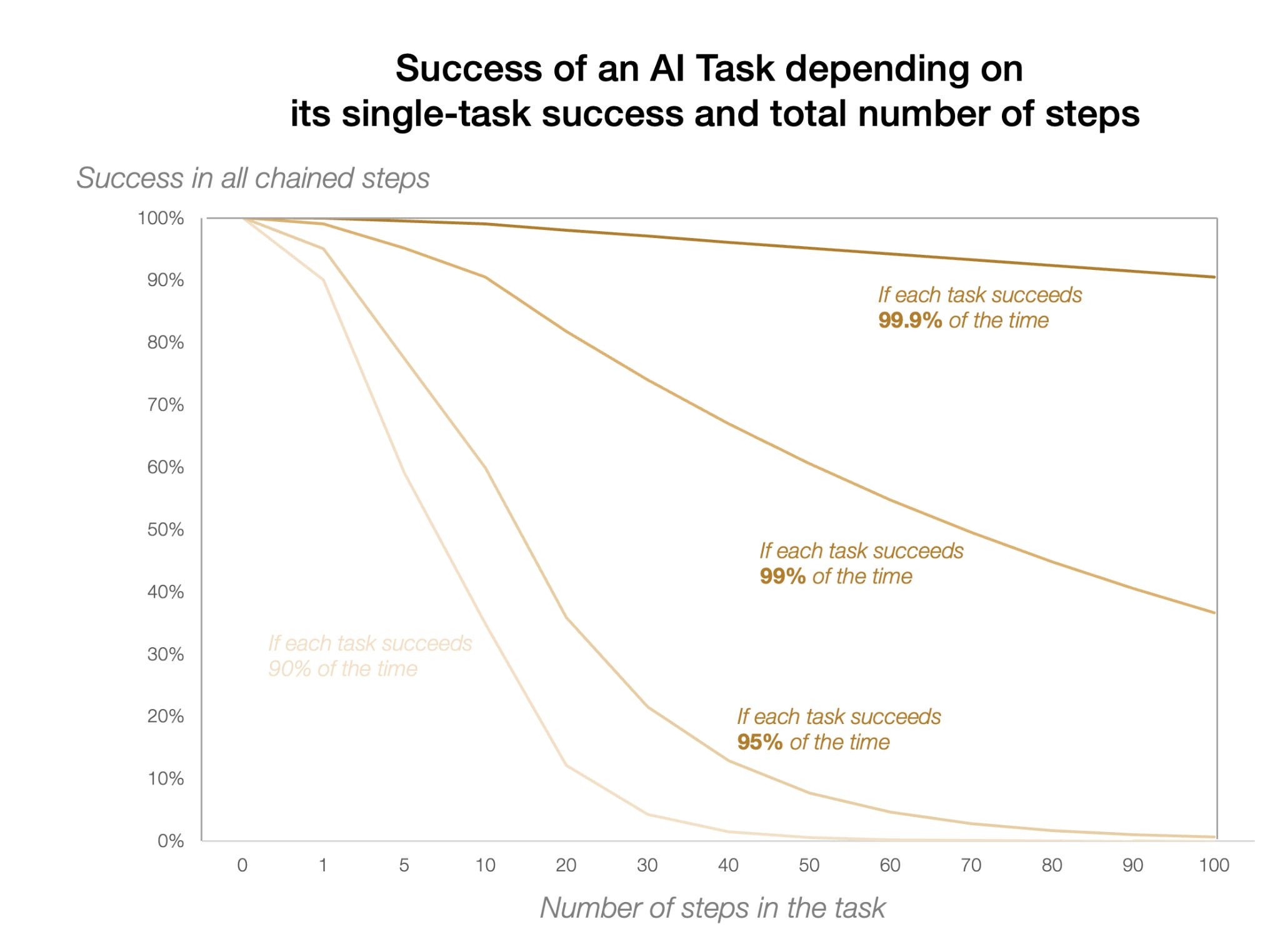
This is why there’s a pretty clear tradeoff between the success rate and the task length in real life:
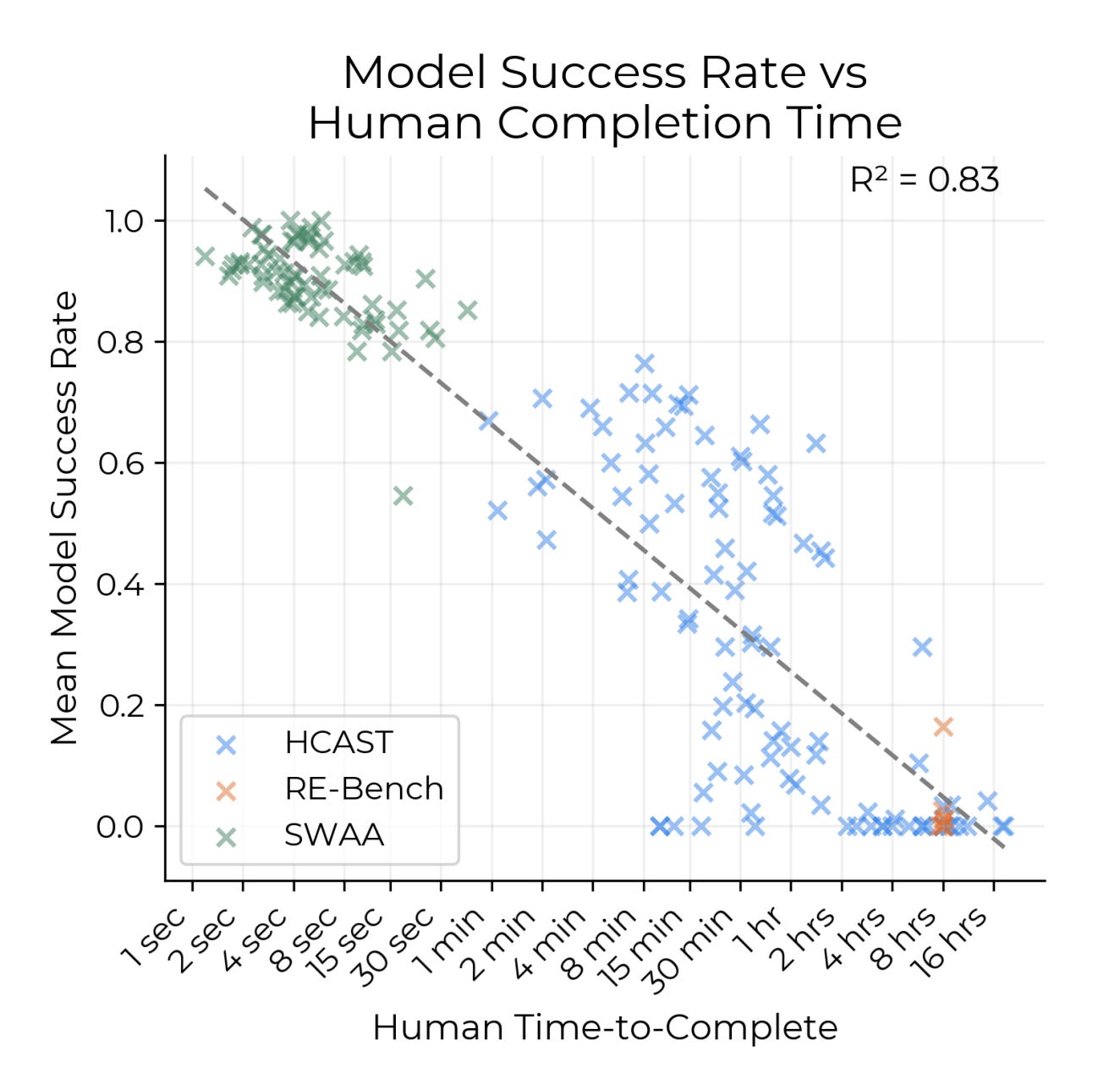
So if you’re keeping the success rate constant, and your task length is doubling every few months, it means the entire line above is moving to the right pretty consistently every few months.
OK and when will that be enough? Do we need to keep improving for one year? Five years? 100?
The Researcher Threshold
It helps to see how AIs perform across domains. What we see time and again is that AIs get to human levels faster and faster, and then surpass them.
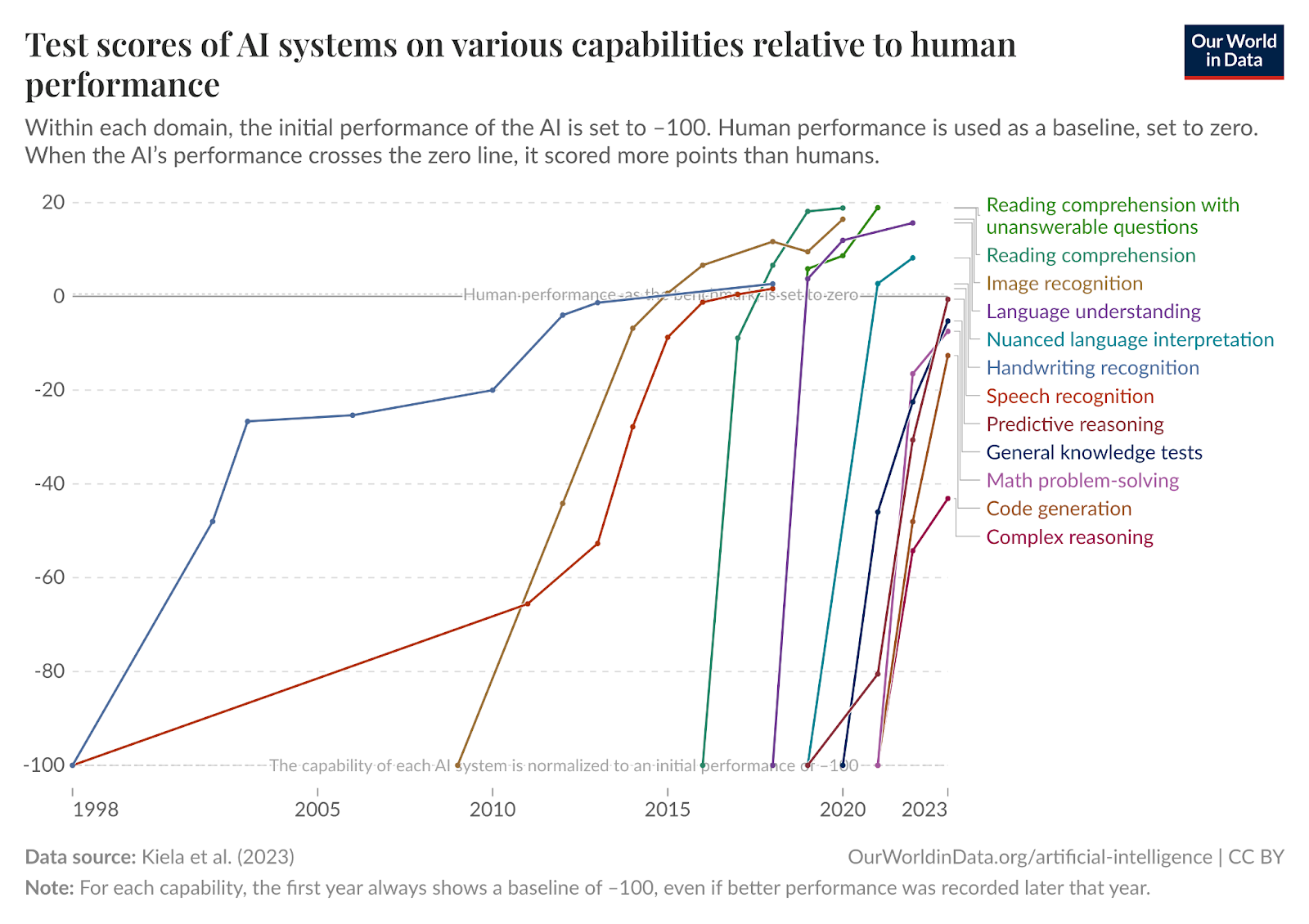
Look at how good GPT got in just one year:
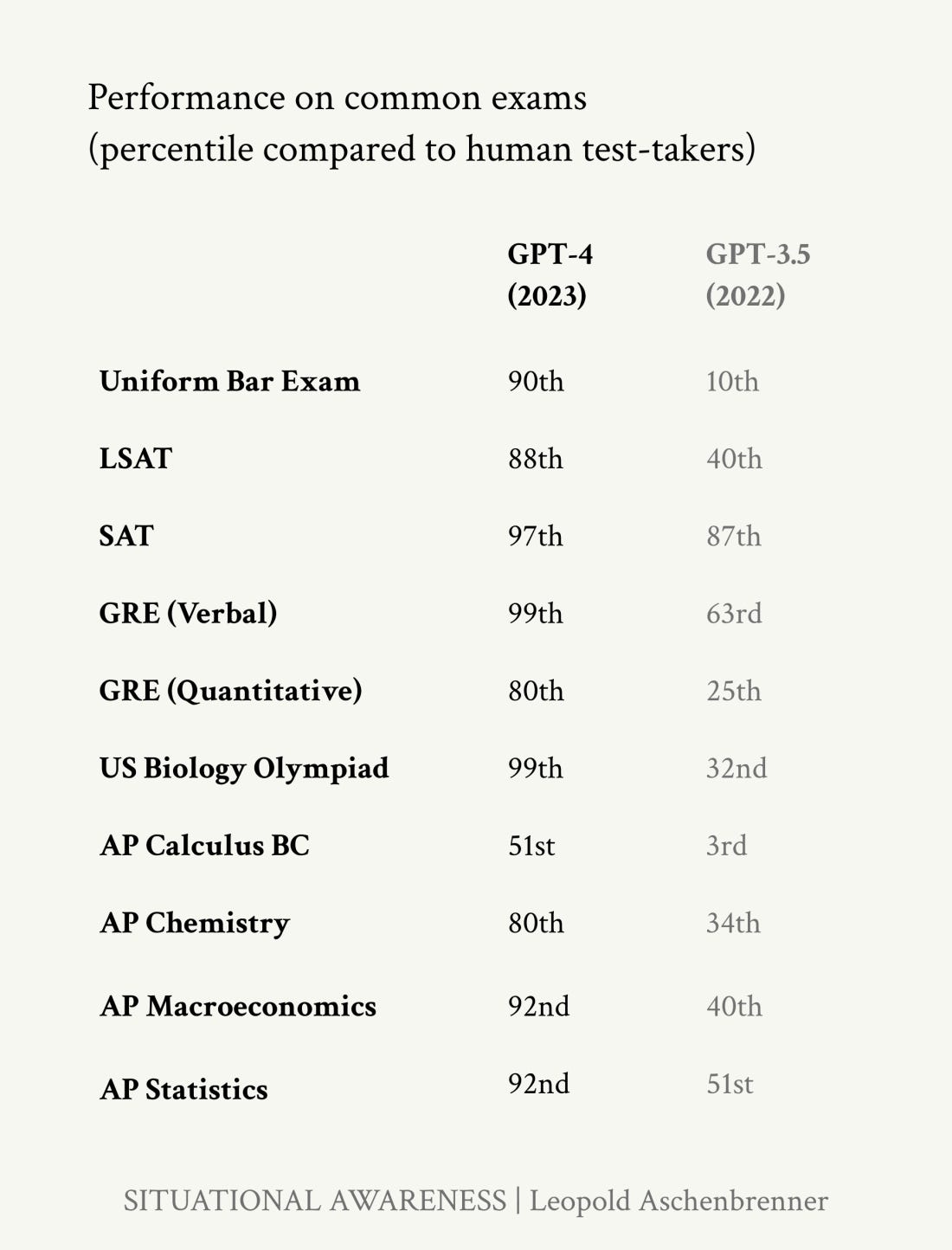
The following benchmarks were designed to compare AIs to experts across different fields:
These AI performance evaluations (“evals”) were designed to last a very long time, but they last less and less. The ultimate eval (named “Humanity’s Last Exam”) was meant to last years or decades by making questions extremely hard for AIs. It hoped to remain relevant until AGI. Instead, in less than a year, GPT has gone from a ~3% score to ~32%.
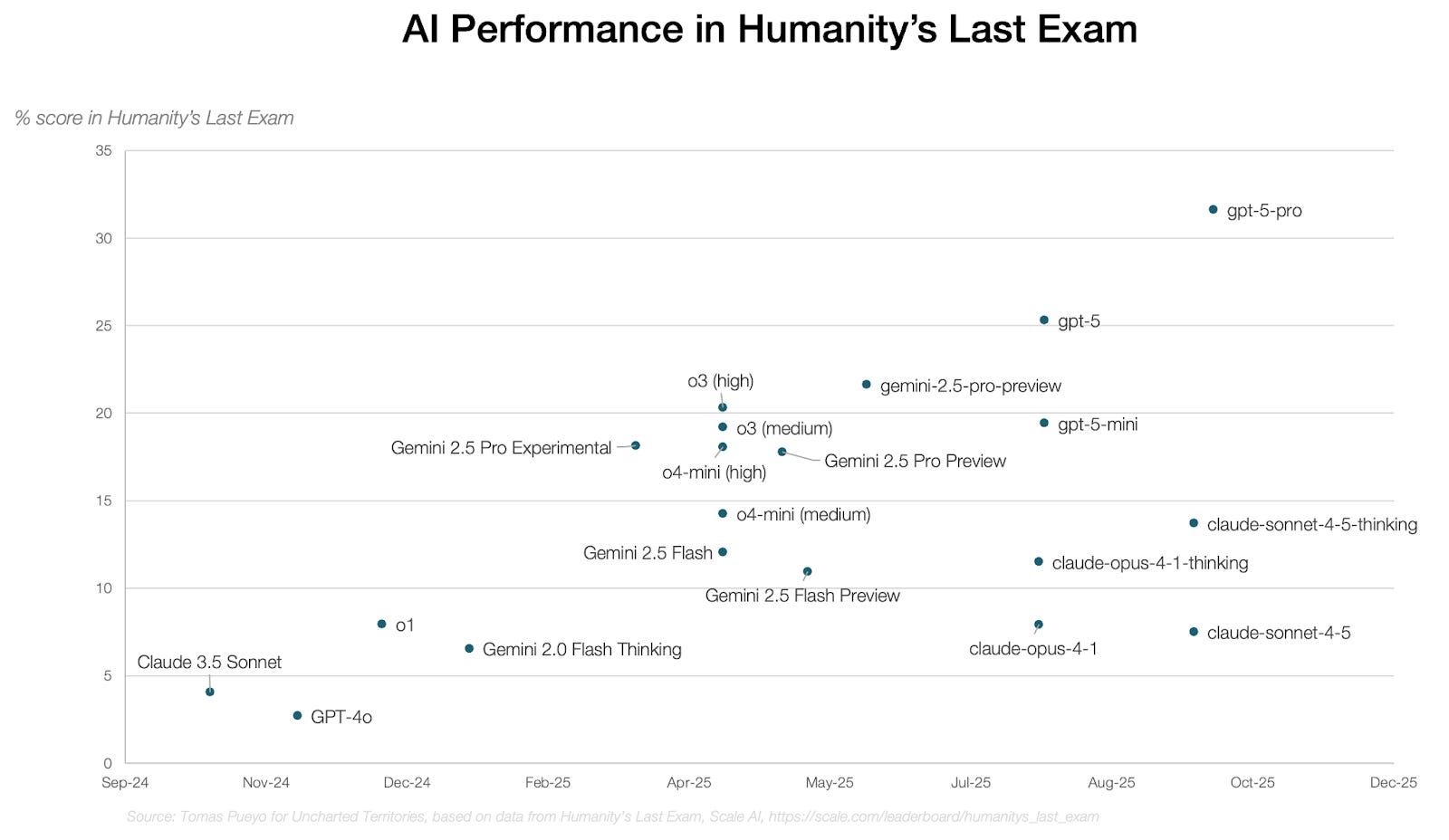
The race to 100% is inexorable.
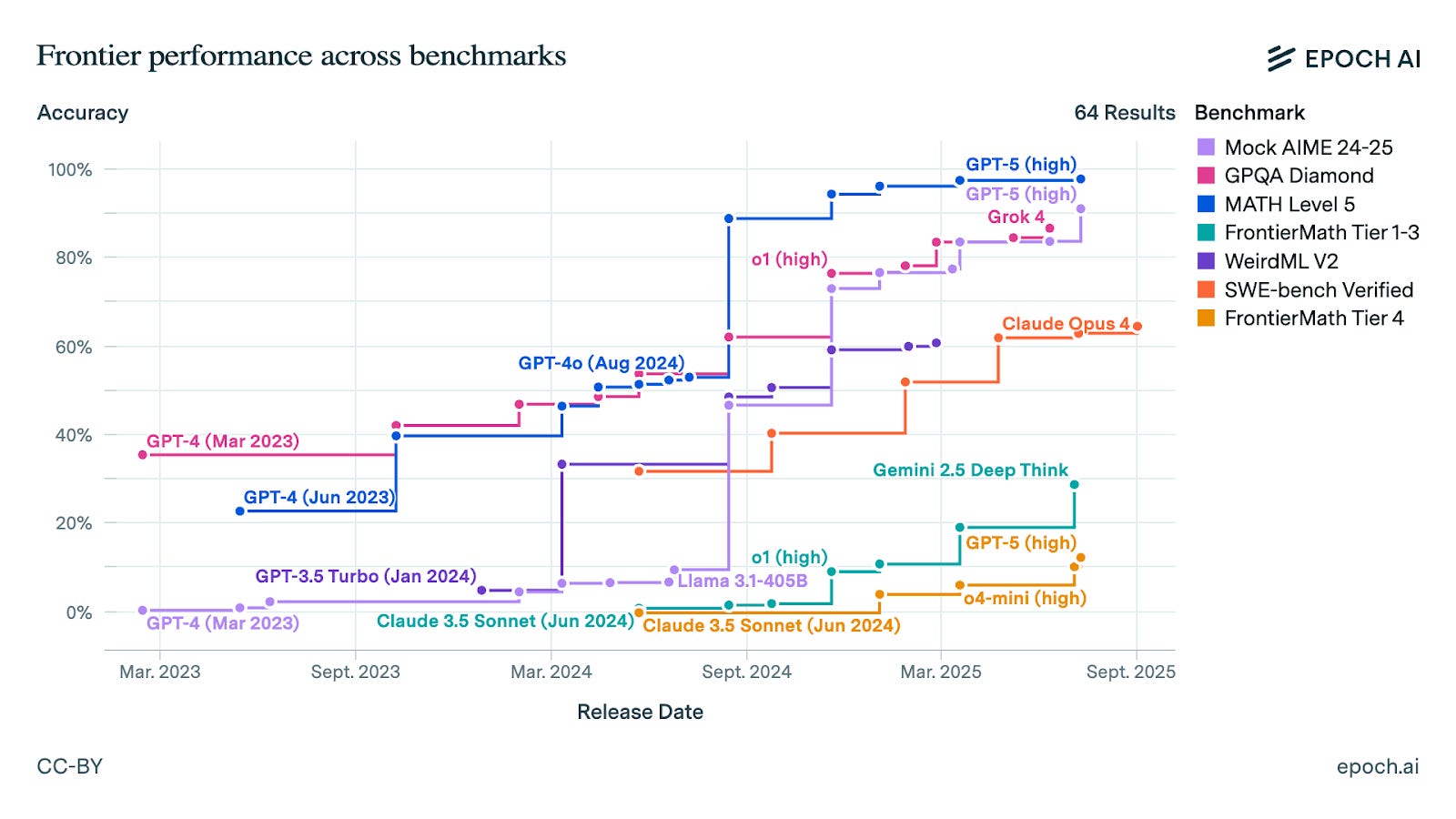
But you know what I think is most revealing? The evals of AI research replacement. Yes, that exists!
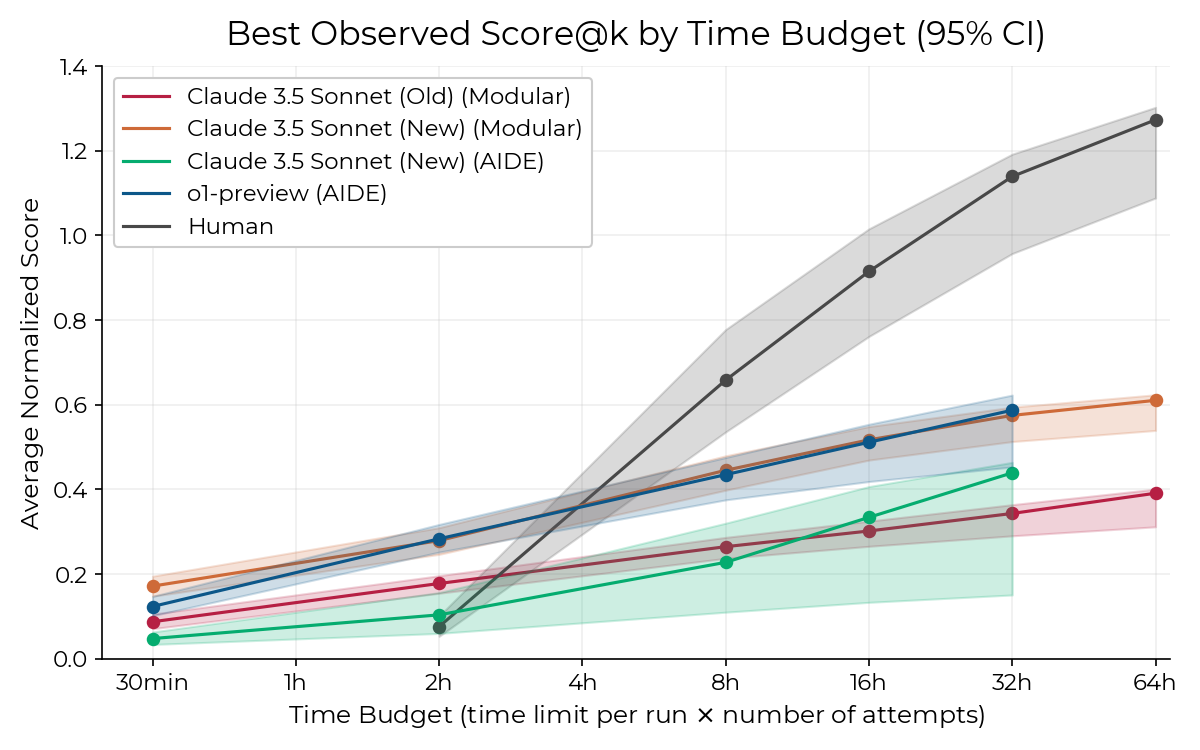
What this graph is telling you is that AIs (in this case, the “very old” Claude 3.5 and o1-preview) beat AI researchers in tasks up to 2-4h, but as AIs and humans are given more time, AI performance increases slowly whereas AI researcher performance goes through the roof. This is why it’s so valuable that AI’s length of tasks keeps improving.
Something similar was discovered in this paper from OpenAI:
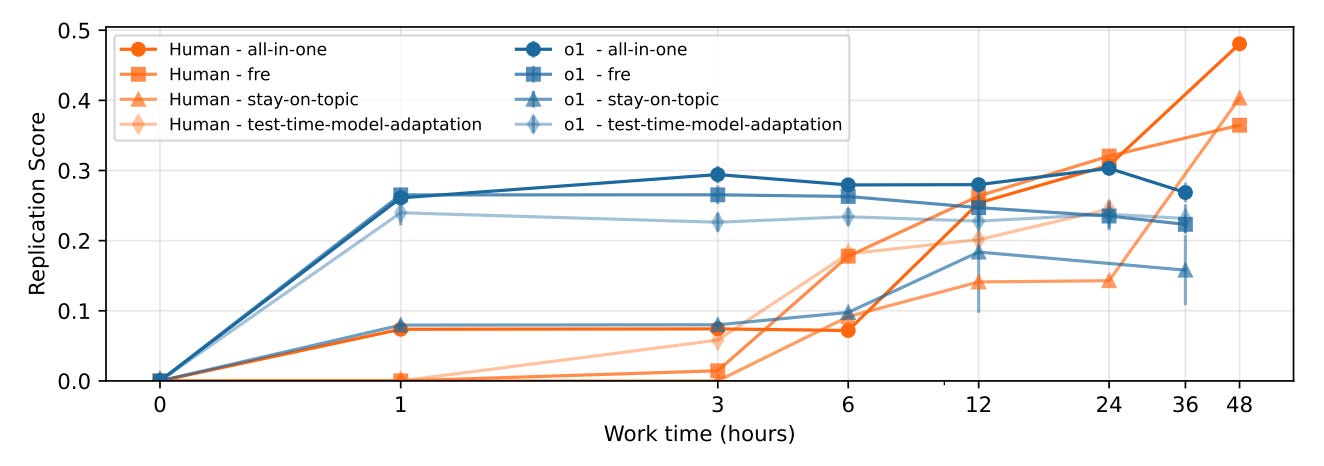
We’re Starting to See It: AI Improving AI
It’s not like AIs improving AIs is a pipe dream, they’ve been doing it for years, and every year it accelerates:
Neural Architecture Search (NAS) uses AI to optimize AI neural networks
AutoML automates the entire neural network creation process, including tasks like data preprocessing, feature engineering, and hyperparameter tuning.
AlphaProof (2024) does math at the International Mathematical Olympiad level, generating proofs that inform AI algorithm design.
And of course, coding:
Anthropic: AI agents now write 90% of code!
OpenAI: “Almost all new code written at OpenAI today is written by Codex users”
Google: AI agents write 50% of code characters.
Meta and Microsoft: ~50% next year and 20-30% today respectively
Seeing these data points, one wonders how AI research is not fully automated yet! This Reddit comment shed some light on it:
I and several people I know went from zero to near zero usage of AI a year or two ago to using it everyday. It saves me time, and even more than that it saves me from doing boring work.
Now, did my productivity increase in any way? Not really. I just have more down time. First: I don’t want to advertise my now available time to my manager because they still think in the old way. And I can guarantee that once they find out how productive I can be, I will get more work, not a raise. So I have little incentive to advertise my newly found productivity increase. Second: even if I could do more, most of the things I work for require other people somewhere in the workflow. And those people have not started using AI at work or don’t use it extensively. It doesn’t matter if it took me 5 minutes instead of two days for a document. It will still take an old geezer somewhere 5 days to get back to me after reviewing it.
AI will get better every day, and AI managers will get better too, maybe automating not just tasks, but their orchestration, until both researchers and managers are all automated, and the speed of progress increases by orders of magnitude.
The Market’s Assessment
To figure out when precisely that might happen, it’s always good to look at prediction markets. According to Metaculus, we will reach their definition of weak AGI by the end of 2027 (as of writing this article):4
Note that the mode for this prediction is September 2026, in 10 months!
The graph below shows when the market guesses we will reach a more demanding definition of AGI:
AGI in 2033. Here again the mode is much earlier, April 2029, in 4 years
The definition of AGI in this second market includes robotics, though, which I think is the reason why the market believes it will take much longer. Without robotics, I believe the market would predict this date to arrive much faster.
The Current Progress Speed Won’t Last
A key argument that Aschenbrenner makes to conclude that AGI will happen within the decade is because we’re going to increase our machines’ ability to think much faster now than in the future:
The ramp up in AI investment we’re making is unsustainable. We can’t keep dedicating more and more money to AI forever.
We’re finding the low-hanging fruits of computer and algorithm optimization.
These two together suggest that, if we are to find AGI, it’s either in the next few years, or it will take dramatically longer.
Matthew Barnett illustrated it visually:
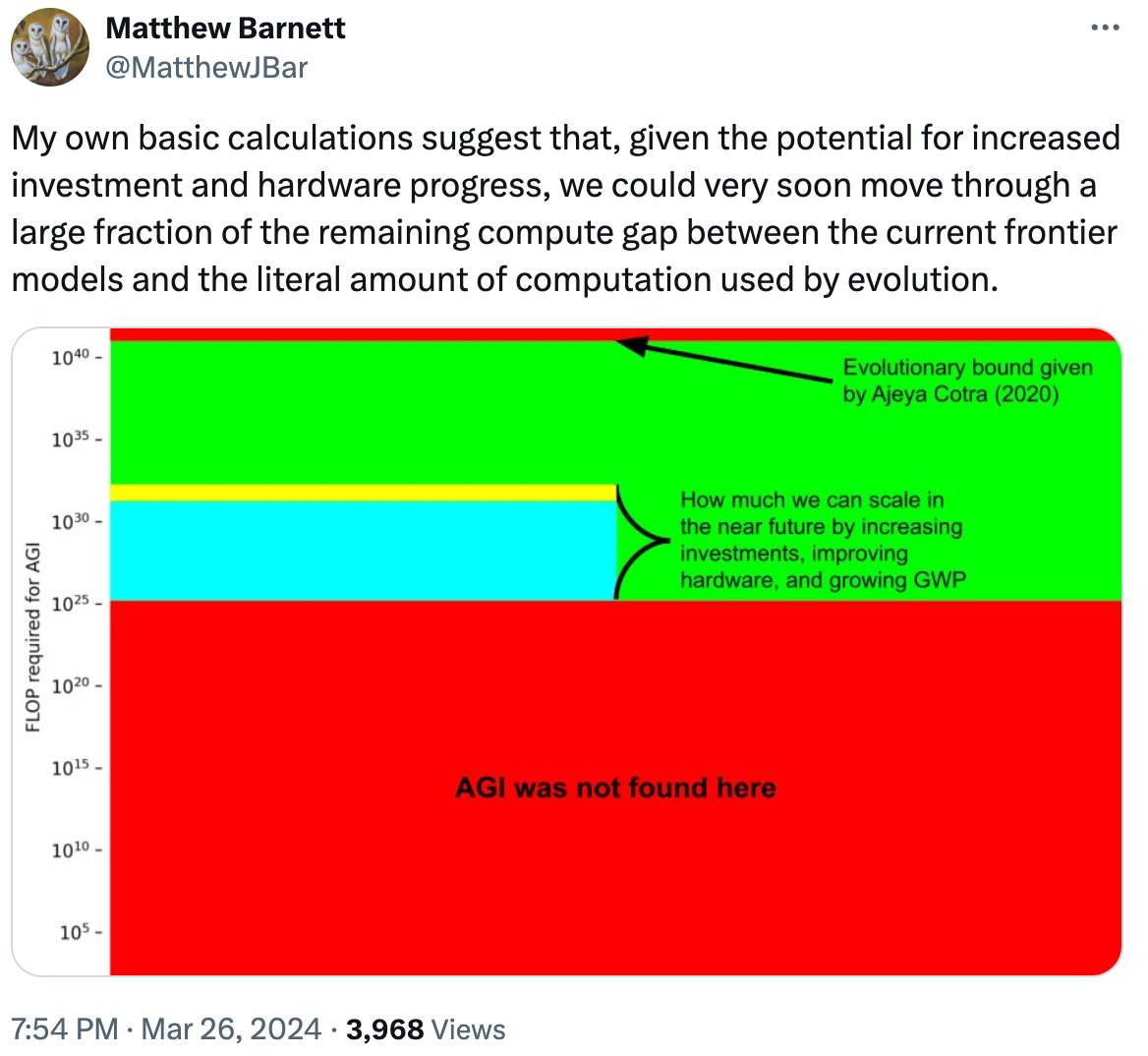
When Do Hyperscalers Think We Will Reach AGI?
Why does all this matter? What we’re saying here is that we’re just a few years away from AGI, and that’s a key reason why hyperscalers are spending so much money on AI. If this were true, then hyperscaler leaders should manifest their belief that AGI will be reached in the next few years, probably before 2030. Do they?
Elon Musk thinks AGI will be reached at the end of this year, or the beginning of next year:
Dario Amodei, CEO of Anthropic, thinks it’s going to be in 2026-2027.
“We will just fall short of 2030 to achieve AGI, and it’ll take a bit longer. But by 2030 there’ll be such dramatic progress… And we’ll be dealing with the consequences, both positive and negative, by 2030.”—Sundar Pichai, CEO of Google and Alphabet
Over the next 5 to 10 years, we’ll start moving towards what we call artificial general intelligence.—Demis Hassabis, CEO DeepMind.
Sam Altman, CEO of OpenAI, believes the path to AGI is solved, and that we will reach it in 2028.
We’re closer than anyone publicly admits.—Sam Altman
So they think it’s coming in 1-10 years, with most of them in the 2-5 range.
Takeaways
The arguments to claim we’re about to make gods are:
AI expertise is growing inexorably. Threshold after threshold, discipline after discipline, it masters it, and then beats humans at it.
We’re now tackling the PhD level.
In the current trajectory, we should reach AI Researcher levels soon.
Once we do, we can automate AI research and turbo-boost it.
If we do that, superintelligence should be around the corner.
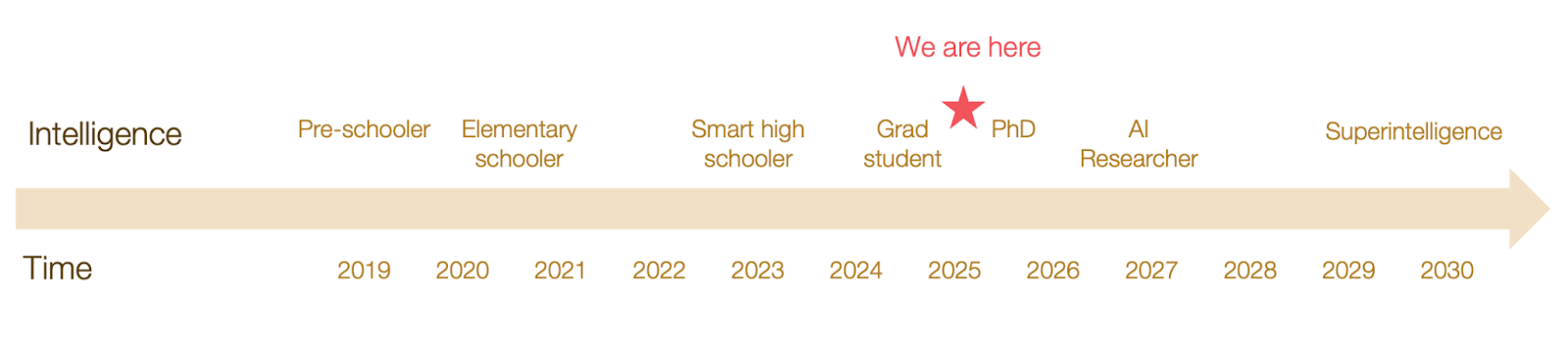
How soon should we expect to reach AI Researcher level?
The past progression suggests it’s a matter of a few years.
We can see this happening, with parts of the AI workflows being automated as we speak.
Markets are consistent with this belief.
What hyperscalers say and what they do is consistent, too.
We’re about to increase effective compute so much that, if it doesn’t happen in the next few years, it might take decades.
You can have two types of disagreements with these statements:
Effective compute won’t keep increasing as it has until now
Even if it does, it won’t be enough to reach AGI
Let’s focus on them in the coming articles and answer the following questions:
Can our compute keep getting better as fast as it has in the past?
What’s the relationship between that and the AI bubble? Does that clarify whether there’s an AI bubble?
Can algorithms keep getting better as fast as they have in the past?
What about the data issue?
What other obstacles are there to AGI?
If we do reach AGI, will we reach superintelligence? Will we reach God?
If we do, what happens next?
As we discussed in the previous article, another is simply that revenue justifies it. But these things are entangled: If we reach AGI, of course money will justify massive amounts of investment, since it will take over huge parts of the economy.
LLMs are really just word prediction machines. Here, test loss measures how well the LLM can predict the next word in a text it has never seen.
This is so weird to me because it’s a sign of how intelligence can emerge in animals, and especially human brains. They’re just a matter of having enough neurons and enough connections between them. It means intelligence emerges, rather than requires delicate design. It makes humans much less magical than people might think. We’ve just stumbled upon the first path to intelligence that nature found, and it found it not because it was especially difficult. It just had to optimize for intelligence for long enough to surf down these lines.
This AGI definition is easier to achieve than ours, but it’s pretty telling we’re getting into the realm of what was defined as AGI a few years ago. The definition in Metaculus: “We define AGI as a single unified software system that can satisfy the following criteria, all easily completable by a typical college-educated human.
Able to reliably pass a Turing test of the type that would win the Loebner Silver Prize.
Able to score 90% or more on a robust version of the Winograd Schema Challenge, e.g. the “Winogrande” challenge or comparable data set for which human performance is at 90+%
Be able to score 75th percentile (as compared to the corresponding year’s human students; this was a score of 600 in 2016) on the full mathematics section of a circa-2015-2020 standard SAT exam, using just images of the exam pages.
Be able to learn the classic Atari game “Montezuma’s revenge” (based on just visual inputs and standard controls) and explore all 24 rooms based on the equivalent of less than 100 hours of real-time play
The 'test loss' series of graphs say that more data is needed to get less mistakes. Today's models are basically trained on the whole internet. Any further data will be marginal (lower-quality). Generally speaking, we have reached the limit of high-quality data to feed the bots, and a large part of the internet right now is already LLM-generated. So we might run out of high-quality data before. Indeed there can be deliberate 'infection' of training data to 'propagandize' LLMs - (https://thebulletin.org/2025/03/russian-networks-flood-the-internet-with-propaganda-aiming-to-corrupt-ai-chatbots/).
The only other source of real data is reality itself, ie real-world data captured by robots in real-world environments, but that will probably require closer to a decade.
Exponential increases are exponential until they are not.... if there is an upper bound in AI intelligence, it results in an s-curve. I'm not claiming necessarily that there IS an upper bound, or where it could be - I don't think humanity even understands intelligence that much to be able to. I AM saying that all these hyperscalers seem to be assuming that there is no such upper bound (or else they are at least presenting it that way to investors)
Thanks, as always.
"When we reach that point, AIs will start taking over full jobs, accelerate the economy, create abundance where there was scarcity, and change society as we know it."
Whenever I hear about how 'we' are going to have this or that benefit for 'us', I think of that joke about the Lone Ranger and Tonto. They're surrounded by ten thousand Lakota and Cheyenne warriors. The Lone Ranger says: "Well, Tonto, it looks like we've reached the end of the trail. We're going to die." Tonto says: "Who's this 'we', white man?"
So who is the 'we'? Who gets the abundance? Who benefits from that changed society? Certainly, the owners of the systems will -- even those of us who own a small piece of those companies. But those who don't? What happens to them when their jobs disappear? Perhaps it's like horse jobs turning into car jobs 100 years ago -- but what if it's not?